


En skalerbar deep learning-tilgang til massive grafer

Figur 1:Udvidelse af kvartererne startende fra den brune knude i midten. Første udvidelse:grøn; andet:gul; tredje:rød.
En grafstruktur er yderst nyttig til at forudsige egenskaber af dens bestanddele. Den mest succesrige måde at udføre denne forudsigelse på er at kortlægge hver enhed til en vektor ved hjælp af dybe neurale netværk. Man kan udlede ligheden mellem to enheder baseret på vektornærheden. En udfordring for dyb læring, imidlertid, er, at man skal indsamle information mellem en enhed og dens udvidede naboskab på tværs af lag af det neurale netværk. Nabolaget udvider sig hurtigt, gør beregningen meget dyr. For at løse denne udfordring, vi foreslår en ny tilgang, valideret gennem matematiske beviser og eksperimentelle resultater, der tyder på, at det er tilstrækkeligt kun at indsamle oplysninger fra en håndfuld tilfældige enheder i hver kvarterudvidelse. Denne betydelige reduktion i områdets størrelse giver samme forudsigelseskvalitet som avancerede dybe neurale netværk, men reducerer træningsomkostningerne i størrelsesordener (f.eks. 10x til 100x mindre beregnings- og ressourcetid), fører til tiltalende skalerbarhed. Vores papir, der beskriver dette arbejde, "FastGCN:Hurtig læring med Graph Convolutional Networks via Importance Sampling, " vil blive præsenteret på ICLR 2018. Mine medforfattere er Tengfei Ma og Cao Xiao.
Kompleksitet af grafanalyse
Grafer er universelle repræsentationer af parvise forhold. I applikationer fra den virkelige verden, de kommer i en række forskellige former, herunder f.eks. sociale netværk, genekspressionsnetværk, og vidensgrafer. Et trendemne inden for dyb læring er at udvide den bemærkelsesværdige succes med veletablerede neurale netværksarkitekturer for euklidiske strukturerede data (såsom billeder og tekster) til uregelmæssigt strukturerede data, inklusive grafer. Grafens konvolutionerende netværk, GCN, er et sådan fremragende eksempel. Det generaliserer begrebet foldning for billeder, som kan betragtes som et gitter af pixels, til grafer, der ikke længere ligner et almindeligt gitter.
Idéen bag GCN er meget enkel. De af os, der tog Signal Processing 101 eller et grundlæggende computersynskursus, kender allerede konceptet med et foldningsfilter. For billeder, det er en lille matrix af tal, skal ganges elementvis med et bevægeligt vindue af billedet, med den resulterende produktsum, der erstatter vinduets midterste nummer. For grafer, dette ligner. En god kombination af filtrene kan detektere primitive lokale strukturer, såsom linjer i forskellige vinkler, kanter, hjørner, og pletter af en bestemt farve. For grafer, viklinger ligner hinanden. Forestil dig, at hver grafknude først er knyttet til en vektor. For hver knude, naboernes vektorer summeres (med visse vægte og transformationer) ind i det. Derfor, alle noder opdateres samtidigt, udfører et lag med fremadrettet udbredelse. Grafviklinger kan bruges til at udbrede information gennem kvarterer, så global information spredes til hver grafknude.
Problemet med GCN er, at for et netværk med flere lag, kvarteret udvides hurtigt, involverer mange vektorer, der skal summeres sammen, for blot en enkelt node. En sådan beregning er uoverkommelig dyr for grafer med et stort antal knudepunkter. Hvor stort vil et udvidet kvarter se ud? I sociale netværksanalyse, der er et berømt koncept opfundet "seks grader af adskillelse, " som siger, at man kan nå enhver anden person på Jorden gennem seks mellemliggende forbindelser! Figur 1 illustrerer, at startende fra den brune knude i midten, udvide kvarteret tre gange (i rækkefølgen af grønt, gul, og rød) berører næsten hele grafen. Med andre ord, Alene opdatering af vektoren for den brune knude er besværlig for en GCN med så få som tre lag.
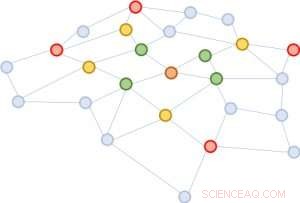
Figur 2:Starter fra den samme brune knude, i hver kvarterudvidelse, vi prøver kun fire noder.
Forenkling for skalerbarhed
Vi foreslår en enkel, men kraftfuld løsning, kaldet FastGCN. Hvis det er dyrt at udvide kvarteret fuldt ud, hvorfor ikke udvide med kun få naboer hver gang? Figur 2 illustrerer konceptet. Startende fra den brune knude, i hver udvidelse vælger vi et konstant antal (fire) knudepunkter og summerer kun vektorerne fra dem. Prøvetagningen reducerer omkostningerne til træning af det neurale netværk væsentligt, ved at reducere træningstiden med størrelsesordener på benchmarkdatasæt, der almindeligvis anvendes af forskere. Endnu, forudsigelser forbliver sammenlignelige nøjagtige. Størrelsen af disse benchmark-grafer varierer fra nogle få tusinde noder til et par hundrede tusinde noder, bekræfter skalerbarheden af vores metode.
Bag denne intuitive tilgang ligger en matematisk teori for tilnærmelse af tabsfunktionen. Et lag af netværket kan opsummeres som en matrixmultiplikation:H'=s(AHW), hvor A er tilstødende matrix af grafen, hver række af H er vektoren knyttet til noderne, W er en lineær transformation af vektorerne (også fortolket som modelparameteren, der skal læres), og rækkerne af H' indeholder de opdaterede vektorer. Vi generaliserer denne matrixmultiplikation til en integraltransformation h'(v)=s(òA(v, u)h(u)W dP(u)) under et sandsynlighedsmål P. Derefter, stikprøven af et fast antal naboer i hver udvidelse er intet andet end en Monte Carlo-tilnærmelse af integralet under målingen P. Monte Carlo-tilnærmelsen giver en konsistent estimator af tabsfunktionen; derfor, ved at tage gradienten, vi kan bruge en standard optimeringsmetode (såsom stokastisk gradientnedstigning) til at træne det neurale netværk.
En række deep learning-applikationer
Vores tilgang adresserer en nøgleudfordring inden for dyb læring til grafer i stor skala. Det gælder ikke kun GCN, men også mange andre grafiske neurale netværk bygget på konceptet om naboskabsudvidelse, en væsentlig komponent i grafrepræsentationslæring. Vi forudser, at løsningen af udfordringen i denne grundlæggende datastruktur - grafer - vil blive vedtaget i en bred vifte af applikationer, herunder analyse af sociale netværk, den dybe indsigt i protein-protein-interaktioner til lægemiddelopdagelse, og kuration og opdagelse af information i vidensbaser.
Sidste artikelBløde udtryk som åben og deling fortæller ikke den sande historie om dine data
Næste artikelGår ud over menneskelige fejl
 Varme artikler
Varme artikler
-
 Boeing siger, at snesevis af 737NG -fly jordede globalt over revnerBoeing siger, at 50 af sine populære 737NG -fly er blevet jordet på grund af revner og skal repareres Boeing meddelte torsdag, at snesevis af sine populære 737NG -fly var taget ud af drift, efter
Boeing siger, at snesevis af 737NG -fly jordede globalt over revnerBoeing siger, at 50 af sine populære 737NG -fly er blevet jordet på grund af revner og skal repareres Boeing meddelte torsdag, at snesevis af sine populære 737NG -fly var taget ud af drift, efter -
 ZTE-lidelser truer, efterhånden som handelsspændingerne mellem USA og Kina stigerDen kinesiske telekomkoncern ZTE står over for en krise efter et amerikansk forbud mod salg af amerikanske komponenter, midt i bredere handelsspændinger mellem Washington og Beijing Med en stor ki
ZTE-lidelser truer, efterhånden som handelsspændingerne mellem USA og Kina stigerDen kinesiske telekomkoncern ZTE står over for en krise efter et amerikansk forbud mod salg af amerikanske komponenter, midt i bredere handelsspændinger mellem Washington og Beijing Med en stor ki -
 Toshiba skråstreg 7, 000 job, nedjusterer resultatudsigterne7, 000 job vil blive nedlagt i Toshiba, annoncerede CEO Nobuaki Kurumatani Chefen for det kæmpende Toshiba sagde torsdag, at han ville skære 7, 000 job i løbet af de næste fem år, da det japanske
Toshiba skråstreg 7, 000 job, nedjusterer resultatudsigterne7, 000 job vil blive nedlagt i Toshiba, annoncerede CEO Nobuaki Kurumatani Chefen for det kæmpende Toshiba sagde torsdag, at han ville skære 7, 000 job i løbet af de næste fem år, da det japanske -
 FDA's gennembrudsstatus for screeningsalgoritme opmuntrer til håb om at markere risici for hjertesv…Kredit:CC0 Public Domain Hjertesvigt opdages oftest ved ekkokardiogram -billeddannelsestest, men disse tests er normalt ikke en del af en rutinemæssig fysisk undersøgelse. Adgang til ekkokardiogra
FDA's gennembrudsstatus for screeningsalgoritme opmuntrer til håb om at markere risici for hjertesv…Kredit:CC0 Public Domain Hjertesvigt opdages oftest ved ekkokardiogram -billeddannelsestest, men disse tests er normalt ikke en del af en rutinemæssig fysisk undersøgelse. Adgang til ekkokardiogra
- Forskere undersøger potentialet for et virkelig decentraliseret energisystem
- NASAs nedbørsbilleder afslører, at Norbert genvinder status for tropisk storm
- Satellitbilleder afslører sammenkoblet VVS -system, der fik Bali -vulkanen til at bryde ud
- Putin udruller ny russisk limousine ved indvielsen
- Biomasseproducenter kan indbringe kontanter, mens de etablerer switchgrass
- Sjælden sangfugl har måske aldrig eksisteret