


Brug af forstærkningslæring til at opnå menneskelignende balancekontrolstrategier i robotter
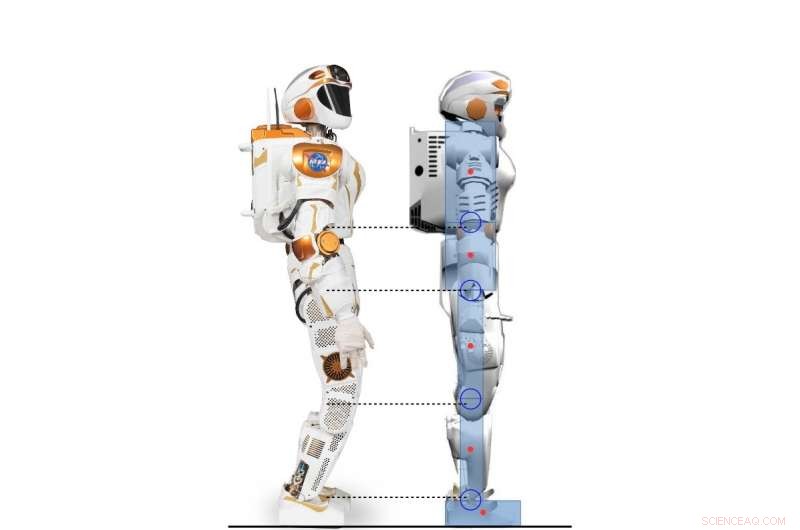
Set fra siden af Valkyrie-robot og den 2D-humanoide karakter modelleret efter Valkyrie-robot. Kredit:Yang, Komura &Li
Forskere ved University of Edinburgh har udviklet en hierarkisk ramme baseret på deep reinforcement learning (RL), der kan tilegne sig en række forskellige strategier til humanoid balancekontrol. Deres rammer, skitseret i et papir, der er forudgivet på arXiv og præsenteret på 2017 International Conference on Humanoid Robotics, kunne udføre langt mere menneskelignende balanceringsadfærd end konventionelle controllere.
Når du står eller går, mennesker bruger naturligt og effektivt en række teknikker til underaktiveret kontrol, der hjælper dem med at holde balancen. Disse omfatter tåvipning og hælrulning, som skaber bedre frihøjde til foden. Replikation af lignende adfærd i humanoide robotter kunne i høj grad forbedre deres motoriske og bevægelsesevner.
"Vores forskning fokuserer på at bruge dyb RL til at løse dynamisk bevægelse af humanoide robotter, "Dr. Zhibin Li, en underviser i robotteknologi og kontrol ved University of Edinburgh, hvem udførte undersøgelsen, fortalte TechXplore. "I fortiden, bevægelse blev hovedsageligt udført ved hjælp af konventionelle analytiske tilgange - modelbaseret, som er begrænsede, fordi de kræver menneskelig indsats og viden, og kræver høj computerkraft for at køre online."
Kræver mindre menneskelig indsats og manuel justering, maskinlæringsteknikker kan føre til udviklingen af mere effektive og specifikke controllere end traditionelle tekniske tilgange. En yderligere fordel ved at bruge RL er, at beregningen af disse værktøjer også kan outsources offline, resulterer i hurtigere online ydeevne for højdimensionelle kontrolsystemer, såsom humanoide robotter.

En simuleret Valkyrie-robot i tå-/hæltiltstilling. Kredit:Yang, Komura &Li
"I betragtning af de stadig stærkere dybe RL-algoritmer, et stigende antal forskningsstudier er begyndt at bruge dyb RL til at løse kontrolopgaver, da de seneste fremskridt inden for dybe RL-algoritmer designet til kontinuerligt handlingsdomæne har frembragt muligheden for at anvende forstærkningslæring kontinuerlige kontrolopgaver, der involverer kompliceret dynamik, " Dr. Li forklarede. "Hovedformålet med vores forskning var at udforske mulighederne for at bruge dyb forstærkende læring til at tilegne sig alsidige kontrolpolitikker, der er sammenlignelige eller bedre end analytiske tilgange, mens der bruges mindre menneskelig indsats."
Rammen udviklet af Dr. Li, i samarbejde med Dr. Taku Komura og Ph.D. studerende Chuanyu Yang, bruger dyb RL til at opnå kontrolpolitikker på højt niveau. Modtager konstant feedback om robottens tilstand, disse strategier muliggør ønskede ledvinkler ved en lavere frekvens.
"På det lave niveau, proportionelle og afledte (PD) regulatorer bruges ved en meget højere kontrolfrekvens for at garantere stabile ledbevægelser, " Ph.D.-studerende Chuanyu sagde. "Inputene til lavniveau PD-controlleren er ønskede ledvinkler produceret af det neurale netværk på højt niveau, og udgangene er de ønskede drejningsmomenter for ledmotorer."
Forskerne testede ydeevnen af deres algoritme og opnåede meget lovende resultater. De fandt ud af, at overførsel af menneskelig viden fra kontroltekniske metoder til belønningsdesignet for RL-algoritmer muliggjorde balancekontrolstrategier, der lignede dem, der blev brugt af mennesker. I øvrigt, efterhånden som RL-algoritmer forbedres gennem en prøve- og fejlproces, automatisk tilpasse sig nye situationer, deres rammer kræver lidt håndjustering eller andre indgreb fra menneskelige ingeniører.
Angiv træk for tobenet. Yang, Komura &Li
"Vores undersøgelse viser, at dyb forstærkningslæring kan være et kraftfuldt værktøj til at producere sammenlignelige balanceringsresultater med resultaterne for en menneskeskabt controller med mindre manuel tuningindsats og kortere tid, "Dr. Li sagde. "Den dybe forstærkende læringsalgoritme, vi udviklede, er endda i stand til at lære opstået menneskelignende adfærd, såsom at vippe rundt om tæer eller hæle, som de fleste ingeniørmetoder ikke er i stand til at udføre."
Dr. Li og hans kolleger arbejder nu på en udvidelse af deres undersøgelse, der anvender RL til en helkrops Valkyrie-robot i en 3-D-simulering. I denne nye forskningsindsats, de var i stand til at generalisere menneskelignende balanceringsstrategier til gang og andre bevægelsesopgaver.
"Til sidst, vi vil gerne anvende denne hierarkiske ramme for at kombinere maskinlæring og robotkontrol på rigtige humanoide robotter, såvel som til andre robotplatforme, " sagde Dr. Li.
© 2018 Tech Xplore
Sidste artikelGoogle ser på fremtiden efter 20 års søgning
Næste artikelEfter årelang venten, Israelere stiger ombord på det nye hurtigtog
 Varme artikler
Varme artikler
-
 Fremskyndelse af livsvidenskabelige og sundhedsopdagelser:Forvandling af data til indsigtParadigm4 giver brugerne mulighed for at integrere data fra kilder som genomisk sekventering, biometriske mål, miljømæssige faktorer, og mere i deres forespørgsler for at muliggøre nye opdagelser på t
Fremskyndelse af livsvidenskabelige og sundhedsopdagelser:Forvandling af data til indsigtParadigm4 giver brugerne mulighed for at integrere data fra kilder som genomisk sekventering, biometriske mål, miljømæssige faktorer, og mere i deres forespørgsler for at muliggøre nye opdagelser på t -
 Adidas løfter resultatudsigterne efter et stærkt kvartalAdidas udpegede Argentina som et svagt punkt, hvor indtægterne blev negativt påvirket af landets valutaelementer Den tyske sportsvareproducent Adidas løftede onsdag sine resultatforventninger for
Adidas løfter resultatudsigterne efter et stærkt kvartalAdidas udpegede Argentina som et svagt punkt, hvor indtægterne blev negativt påvirket af landets valutaelementer Den tyske sportsvareproducent Adidas løftede onsdag sine resultatforventninger for -
 Varmerør smadrer formen i keramikVarmerørs varmeveksler. Kredit:Brunel University Heat-pipe-teknologi giver næring til en ny generation af lavenergi-, lavemissionsovne, der omstøber Europas verdensførende keramikindustri til en m
Varmerør smadrer formen i keramikVarmerørs varmeveksler. Kredit:Brunel University Heat-pipe-teknologi giver næring til en ny generation af lavenergi-, lavemissionsovne, der omstøber Europas verdensførende keramikindustri til en m -
 Lad dig ikke narre af falske billeder og videoer onlineNix, ikke en rigtig nyhedsrapport fra orkanen Irma. Kredit:Snopes En måned før det amerikanske præsidentvalg i 2016, der blev udgivet en Access Hollywood-optagelse af Donald Trump, hvor han blev h
Lad dig ikke narre af falske billeder og videoer onlineNix, ikke en rigtig nyhedsrapport fra orkanen Irma. Kredit:Snopes En måned før det amerikanske præsidentvalg i 2016, der blev udgivet en Access Hollywood-optagelse af Donald Trump, hvor han blev h
- Kulilte fra naturbrande i Californien driver østpå
- Forfining af akustiske sensorer til detektering af sikker komponenttolerance
- Millimeterbølge fotonik med terahertz halvlederlasere
- Et biologisk inspireret bånd bruger nogle af naturens tricks til at holde fast
- Forskere foreslår en ny strategi til at regulere cellekommunikationsnetværket
- Når flere knogledannende celler er lig med mindre knogle