


En dyb læringsmetode til at identificere Twitter -brugeres placering under nødsituationer
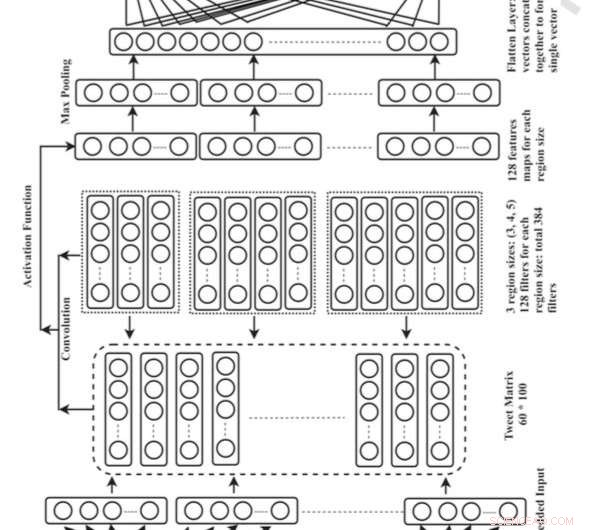
Overordnet arkitektur for det konvolutionelle neurale netværk (CNN). Kredit:Singh og Kumar.
Forskere ved National Institute of Technology Patna, i Indien, for nylig har udviklet et værktøj til at identificere den geografiske placering af nødsituationer og katastrofer, såvel som de mennesker, der er involveret i dem. Deres tilgang, skitseret i et papir i International Journal of Disaster Risk Reduction , udtrækker lokalitetsoplysninger fra tweets ved hjælp af en konvolutionsbaseret neuralt netværk (CNN) -baseret model.
"I nødstilfælde begivenhedernes geografiske placeringsoplysninger, såvel som de berørte brugeres er meget vigtige, "Jyoti Prakash Singh, en af forskerne, der gennemførte undersøgelsen, fortalte TechXplore. "At identificere denne geografiske placering er en udfordrende opgave, da tilgængelige placeringsfelter som brugerplacering og tweets stednavn ikke er pålidelige. Brugernes præcise GPS -placering er sjælden i tweets, og også nogle gange ukorrekt med hensyn til spatiotemporal information. "
Mennesker ramt af naturkatastrofer eller andre nødsituationer deler ofte deres placering på sociale medier, beder om hjælp. Disse oplysninger kan hjælpe reaktionsenheder og lokale myndigheder med at opdage begivenheder tidligt, finde ofre og hjælpe dem. Imidlertid, at udtrække placeringsrelaterede data fra tweets er en meget udfordrende opgave, da disse ofte er skrevet på ikke-standard engelsk og indeholder grammatiske fejl, stavefejl eller forkortelser.
"Det er næsten umuligt for menneskelige operatører, der sporer tweets, at gennemgå hver tweet og finde de stedoplysninger, der er nævnt i dem, "Singh sagde." Dette motiverede os til at udvikle en løsning til automatisk at udtrække placeringsoplysninger fra tweets, der bad om hjælp. I dette arbejde, vi brugte dyb læring til at afgøre, om et tweet indeholder placeringsnavne og fremhæve disse ord. "
Singh og hans kollega Abhivan Kumar udviklede en CNN -model, der kan identificere brugernes placering ved at analysere indholdet af deres tweets. De valgte denne specifikke deep learning -tilgang, fordi den automatisk kan lære den bedste repræsentation af inputdata og bruge denne til at identificere placeringsreferencer.
"Vi brugte en ordindlejringsteknik til at repræsentere tweets på inputlaget i CNN, og lokalitetsreferencer, der findes i tweetet, er repræsenteret i outputlaget i form af en nul-en-vektor, "Singh forklaret." Stedordene er kodet som 1, og ordene uden lokalitet er kodet som 0. Vi brugte flere kombinationer af 2 gram, 3 gram, 4 gram, og 5-gram filtre til at udtrække funktioner fra tweetet. Efter uddannelse til modellen for de 100 epoker, det er i stand til at forudsige de stedreferencer, der er nævnt i tweetet med imponerende nøjagtighed. "
I en indledende evaluering, CNN-modellen udarbejdet af Singh og Kumar var i stand til at udtrække alle placeringsrelaterede ord fra tweets med meget høj nøjagtighed, selv når teksten i et tweet var støjende. Forskerne testede deres model på tweets, der ikke var forudbehandlet og indeholdt grammatiske fejl, stavefejl, forkortelser, og andre forvirrende faktorer.
"Den vigtigste praktiske betydning af vores arbejde er, at det let kan røres, ved hjælp af hændelsesdetekteringsmodeller, "Singh sagde." Hændelsesdetekteringsmodeller kan identificere tweets, der er relateret til den nævnte katastrofe, og vores model kan udtrække placeringen af ofrene, der er berørt af den katastrofe. "
I fremtiden, CNN -modellen udviklet af forskerne kan hjælpe med hurtigt at finde nødsituationer og mennesker, der har brug for akut hjælp. Den samme tilgang kunne også anvendes på borgerlige uroligheder, målrettet annoncering, observere regional menneskelig adfærd, realtids vejtrafikstyring og andre lokationsbaserede tjenester.
"I dette arbejde overvejede vi kun engelsksprogede tweets, men under en krise sender brugerne også tweets på deres regionale sprog, "Singh sagde." Vi arbejder derfor på en model, der adresserer denne flersprogede begrænsning, samtidig med at han også forsøger at udvikle en halvtilsynet model for at reducere spørgsmålet om datamærkning. "
© 2018 Science X Network
 Varme artikler
Varme artikler
-
 Forskere udvikler innovative, mere omkostningseffektiv metode til fremstilling af lægemidlerZinia Jaman, en doktorgradsstuderende ved Purdue University i kemi, forbereder et reaktorsystem som en del af processen til fremstilling af generisk lomustin ved hjælp af en kontinuerlig fremstillings
Forskere udvikler innovative, mere omkostningseffektiv metode til fremstilling af lægemidlerZinia Jaman, en doktorgradsstuderende ved Purdue University i kemi, forbereder et reaktorsystem som en del af processen til fremstilling af generisk lomustin ved hjælp af en kontinuerlig fremstillings -
 Emoji-guder godkender hudfarvemuligheder for par af farverDenne udaterede illustration leveret af Tinder/Emojination viser nye variationer af interracial emoji-par. I emojis-verdenen, interracial par havde stort set ingen muligheder med hensyn til hudfarve.
Emoji-guder godkender hudfarvemuligheder for par af farverDenne udaterede illustration leveret af Tinder/Emojination viser nye variationer af interracial emoji-par. I emojis-verdenen, interracial par havde stort set ingen muligheder med hensyn til hudfarve. -
 Poker ansigt fjernet af new-age techChefforsker ved Dolby Laboratories Poppy Crum siger, at sensorer kombineret med kunstig intelligens kan afsløre, om nogen lyver, forelsket, eller klar til vold Dolby Laboratories chefforsker Poppy
Poker ansigt fjernet af new-age techChefforsker ved Dolby Laboratories Poppy Crum siger, at sensorer kombineret med kunstig intelligens kan afsløre, om nogen lyver, forelsket, eller klar til vold Dolby Laboratories chefforsker Poppy -
 Sådan øger du din internethastighed, når alle arbejder hjemmefraKredit:Shutterstock Med #StayAtHome og social distancering er nu blevet en livsstil, et stigende antal mennesker er afhængige af internettet for at arbejde, uddannelse og underholdning. Dette har
Sådan øger du din internethastighed, når alle arbejder hjemmefraKredit:Shutterstock Med #StayAtHome og social distancering er nu blevet en livsstil, et stigende antal mennesker er afhængige af internettet for at arbejde, uddannelse og underholdning. Dette har
- Isotoper i tænder antyder, at to megalitiske kulturer var separate grupper
- Stirrer på stjernestøv
- Amerikansk-europæisk havovervågning af satellitopsendelser i kredsløb
- Uber-aktien fortsætter med at glide på den første hele handelsdag
- Hvad er vinkler til højde og depression?
- Emerging markets sakker bagud i kapløbet om grøn kapital