


Kunstige neurale netværk gør livet lettere for høreapparatbrugere

Kredit:Oticon
For mennesker med høretab, det kan meget svært at forstå og adskille stemmer i støjende omgivelser. Dette problem kan snart være historie takket være en ny banebrydende algoritme, der er designet til at genkende og adskille stemmer effektivt i ukendte lydmiljøer.
Mennesker med normal hørelse er normalt i stand til at forstå hinanden uden anstrengelse, når de kommunikerer i støjende omgivelser. Imidlertid, for mennesker med høretab, det er meget udfordrende at forstå og adskille stemmer i støjende omgivelser, og et høreapparat kan virkelig hjælpe. Men der er stadig et stykke vej igen, når det kommer til generel lydbehandling i høreapparater, forklarer Morten Kolbæk:
"Når scenariet er kendt på forhånd, som i visse kliniske testopsætninger, eksisterende algoritmer kan allerede slå menneskelig præstation, når det kommer til at genkende og skelne højttalere. Imidlertid, i normale lyttesituationer uden forudgående viden, den menneskelige auditive hjerne forbliver den bedste maskine."
Men det er netop det, Morten Kolbæk har arbejdet på at ændre med sin nye algoritme.
"På grund af dens evne til at fungere i ukendte miljøer med ukendte stemmer, anvendeligheden af denne algoritme er så meget stærkere end hvad vi har set med tidligere teknologi. Det er et vigtigt skridt fremad, når det kommer til at løse udfordrende lyttesituationer i hverdagen, siger en af Morten Kolbæks to vejledere, Jesper Jensen, Seniorforsker ved Oticon og professor ved Center for Akustisk Signalbehandlingsforskning (CASPR) på AAU.
Professor Zheng-Hua Tan, som også er tilknyttet CASPR og supervisor for projektet, er enige om algoritmens store potentiale inden for forsvarlig forskning.
"Nøglen til succes for denne algoritme er dens evne til at lære af data og derefter konstruere kraftfulde statistiske modeller, der er i stand til at repræsentere komplekse lyttesituationer. Dette fører til løsninger, der fungerer meget godt selv i nye og ukendte lyttesituationer, " forklarer Zheng-Hua Tan.
Støjreduktion og taleadskillelse
Specifikt, Morten Kolbæks ph.d. projektet har beskæftiget sig med to forskellige, men velkendte lyttescenarier.
Det første spor tager sigte på at løse udfordringerne ved en-til-en-samtaler i støjende rum som f.eks. bilkabiner. Høreapparatbrugere møder jævnligt sådanne udfordringer.
"For at løse dem, vi har udviklet algoritmer, der kan forstærke højttalerens lyd og samtidig reducere støjen markant uden forudgående viden om lyttesituationen. De nuværende høreapparater er forprogrammeret til en række forskellige situationer, men i det virkelige liv, miljøet ændrer sig konstant og kræver et høreapparat, der er i stand til at aflæse den specifikke situation med det samme, " forklarer Morten Kolbæk.
Projektets andet spor kredser om taleadskillelse. Dette scenarie involverer flere talere, og høreapparatbrugeren kan være interesseret i at høre nogle eller alle af dem. Løsningen er en algoritme, der kan adskille stemmer og samtidig reducere støj. Dette spor kan betragtes som en forlængelse af det første spor, men nu med to eller flere stemmer.
"Man kan sige, at Morten fandt ud af, at ved at justere et par ting her og der, algoritmen fungerer med flere ukendte højttalere i støjende omgivelser. Begge Mortens forskningsspor er betydningsfulde og har tiltrukket sig stor opmærksomhed. siger Jesper Jensen.
Dybe neurale netværk
Metoden, der bruges til at skabe algoritmerne, kaldes "deep learning, " som falder ind under maskinlæringskategorien. Mere specifikt, Morten Kolbæk har arbejdet med dybe neurale netværk, en type algoritme, som du træner ved at give den eksempler på de signaler, den vil støde på i den virkelige verden.
"Hvis, for eksempel, vi taler om tale-i-støj, du giver algoritmen et eksempel på en stemme i et støjende miljø og en af stemmen uden støj. På denne måde Algoritmen lærer at behandle det støjende signal for at opnå et klart stemmesignal. Du fodrer netværket med tusindvis af eksempler, og under denne proces, det vil lære at behandle en given stemme i et realistisk miljø, " forklarer Jesper Jensen.
"Krften ved dyb læring kommer fra dens hierarkiske struktur, der er i stand til at transformere støjende eller blandede stemmesignaler til rene eller adskilte stemmer gennem lag-for-lag-behandling. Den udbredte brug af dyb læring i dag skyldes tre hovedfaktorer:altid- øget regnekraft, stigende mængde big data til træningsalgoritmer og nye metoder til træning af dybe neurale netværk, " siger Zheng-Hua Tan.
En computer bag øret
En ting er at udvikle algoritmen, en anden er at få det til at fungere i et egentligt høreapparat. I øjeblikket, Morten Kolbæks algoritme til taleadskillelse fungerer kun i større skala.
"Når det kommer til høreapparater, udfordringen er altid at få teknologien til at fungere på en lille computer bag øret. Og lige nu, Det kræver Mortens algoritme for meget plads. Selvom Mortens algoritme kan adskille flere ukendte stemmer fra hinanden, det er ikke i stand til at vælge, hvilken stemme der skal præsenteres for høreapparatbrugeren. Så der er nogle praktiske problemer, som vi skal løse, før vi kan introducere det i en høreapparatløsning. Imidlertid, det vigtigste er, at disse problemer nu ser ud til at kunne løses."
Cocktailparty-fænomenet
Mennesker med normal hørelse er ofte i stand til at fokusere på én taler af interesse, selv i akustisk vanskelige situationer, hvor andre mennesker taler samtidigt. Kendt som cocktailparty-fænomenet, problemet har skabt et meget aktivt forskningsområde om, hvordan den menneskelige hjerne er i stand til at løse dette problem så godt. Med denne ph.d. projekt, vi er et skridt tættere på at løse dette problem, Jesper Jensen forklarer:
"Man hører nogle gange, at cocktailparty-problemet er løst. Sådan er det endnu ikke. Hvis miljøet og stemmerne er helt ukendte, hvilket ofte er tilfældet i den virkelige verden, den nuværende teknologi kan simpelthen ikke matche den menneskelige hjerne, som fungerer ekstremt godt i ukendte miljøer. Men Mortens algoritme er et stort skridt i retning af at få maskiner til at fungere og hjælpe mennesker med normal hørelse og dem med høretab i sådanne miljøer, " han siger.
 Varme artikler
Varme artikler
-
 Virus bringer luftfartens fremtid i fare uden statsstøtte:LufthansaKredit:CC0 Public Domain Den øverste direktør for den tyske luftfartsgigant Lufthansa advarede torsdag om, at regeringer muligvis skal redde branchen fra coronavirus -krisen, som drastiske nedskæri
Virus bringer luftfartens fremtid i fare uden statsstøtte:LufthansaKredit:CC0 Public Domain Den øverste direktør for den tyske luftfartsgigant Lufthansa advarede torsdag om, at regeringer muligvis skal redde branchen fra coronavirus -krisen, som drastiske nedskæri -
 Netflix accepterede endelig i Hollywood -klub - men ikke fuldt udNetflix fik 15 Oscar -nomineringer, 10 af dem til Alfonso Cuarons Roma - inklusive dens første bedste billedknik Ved at tjene sin første Oscar-nominering nogensinde for bedste billede med Roma, Ne
Netflix accepterede endelig i Hollywood -klub - men ikke fuldt udNetflix fik 15 Oscar -nomineringer, 10 af dem til Alfonso Cuarons Roma - inklusive dens første bedste billedknik Ved at tjene sin første Oscar-nominering nogensinde for bedste billede med Roma, Ne -
 Nye big data-algoritmer forbedrer jordskælvsdetektion; overvåge husdyrs sundhed og skadedyr i land…Kredit:CC0 Public Domain To nye algoritmer kan hjælpe jordskælvs tidlige varslingssystemer med at give dig et par ekstra sekunder til at slippe, dække over, og hold fast inden jorden begynder at r
Nye big data-algoritmer forbedrer jordskælvsdetektion; overvåge husdyrs sundhed og skadedyr i land…Kredit:CC0 Public Domain To nye algoritmer kan hjælpe jordskælvs tidlige varslingssystemer med at give dig et par ekstra sekunder til at slippe, dække over, og hold fast inden jorden begynder at r -
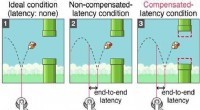 Spil spil uden forsinkelseFigur 1. Oversigt over geometrisk kompensation Et af de mest udfordrende spørgsmål for gamere ser ud til at blive løst snart med indførelsen af et spilmiljø med nul latens. Et KAIST-team udvikle
Spil spil uden forsinkelseFigur 1. Oversigt over geometrisk kompensation Et af de mest udfordrende spørgsmål for gamere ser ud til at blive løst snart med indførelsen af et spilmiljø med nul latens. Et KAIST-team udvikle
- Luftforurening gør os måske mindre intelligente
- Teoretikere beviser endelig, at krøllede pile fortæller sandheden om kemiske reaktioner
- Forskere kortlægger krystaller for at fremme behandlinger for slagtilfælde, diabetes, demens
- Trump trækker forureningsreglerne tilbage for boring på amerikanske jorder
- Hvorfor sprogteknologi ikke kan håndtere Game of Thrones (endnu)
- Sådan ser du det spektakulære Geminid Meteor -brusebad