


En tilgang til at forbedre spørgsmålssvar (QA) modeller
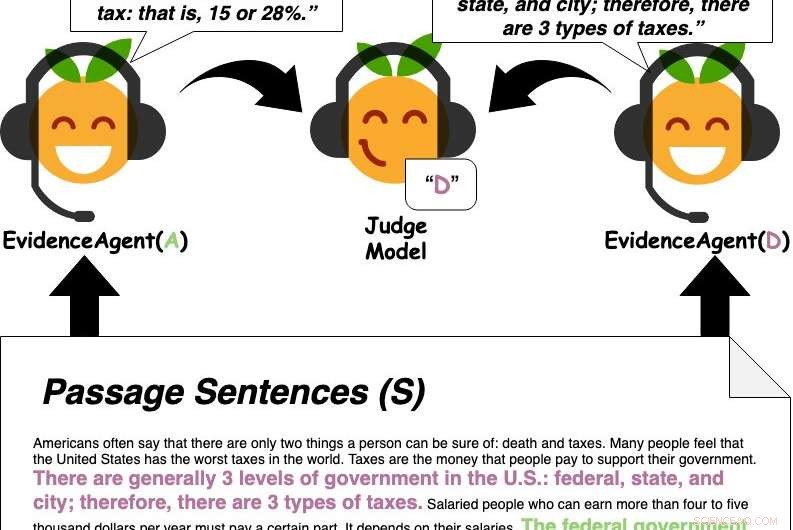
Bevisagenter citerer sætninger fra passagen for at overbevise en dommermodel, der besvarer spørgsmål, om et svar. Kredit:Perez et al.
At identificere det rigtige svar på et spørgsmål indebærer ofte indsamling af store mængder information og forståelse af komplekse ideer. I en nylig undersøgelse, et team af forskere ved New York University (NYU) og Facebook AI Research (FAIR) undersøgte muligheden for automatisk at afdække de underliggende egenskaber ved problemer såsom besvarelse af spørgsmål ved at undersøge, hvordan maskinlæringsmodeller lærer at løse relaterede opgaver.
I deres papir, forudgivet på arXiv og skal præsenteres på EMNLP 2019, de introducerede en tilgang til at indsamle de stærkeste understøttende beviser for et givet svar på et spørgsmål. De anvendte specifikt denne metode til opgaver, der involverer passage-baseret spørgsmål besvarelse (QA), hvilket indebærer at analysere store mængder tekst for at identificere det bedste svar på et givent spørgsmål.
"Når vi stiller et spørgsmål, vi er ofte ikke kun interesserede i svaret, men også hvorfor det svar er rigtigt – hvilke beviser understøtter det svar, "Ethan Perez, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "Desværre, at finde beviser kan være tidskrævende, hvis det kræver at læse mange artikler, forskningsartikler, osv. Vores mål var at udnytte maskinlæring til at finde beviser automatisk."
Først, Perez og hans kolleger trænede en QA-maskinelæringsmodel designet til at besvare brugerspørgsmål på en stor database med tekst, der inkluderede nyhedsartikler, biografier, bøger og andet onlineindhold. Efterfølgende de brugte "evidensagenter" til at identificere sætninger, der ville "overbevise" maskinlæringsmodellen til at svare på en bestemt forespørgsel med et specifikt svar, i det væsentlige at samle beviser for svaret.

Kredit:Perez et al.
"Vores system kan finde beviser for ethvert svar - ikke kun det svar, som Q&A-modellen mener er korrekt, som tidligere arbejde fokuseret på, " sagde Perez. "Således, vores tilgang kan udnytte en Q&A-model til at finde nyttige beviser, selvom Q&A-modellen forudsiger det forkerte svar, eller hvis der ikke er et klart rigtigt svar."
I deres tests, Perez og hans kolleger observerede, at maskinlæringsmodeller typisk vælger beviser fra tekstpassager, der generaliserer godt til at overbevise andre modeller og endda mennesker. Med andre ord, deres resultater tyder på, at modeller foretager vurderinger baseret på lignende beviser som dem, der typisk betragtes af mennesker, og til en vis grad, det er endda muligt at undersøge, hvordan folk tænker, ved at påvirke, hvordan modeller overvejer beviser.
Forskerne fandt også ud af, at mere nøjagtige QA-modeller har en tendens til at finde bedre understøttende beviser, i hvert fald ifølge en gruppe menneskelige deltagere, de interviewede. Maskinlæringsmodellers ydeevne og muligheder kan derfor være stærkt forbundet med deres effektivitet til at indsamle beviser for at understøtte deres forudsigelser.
-

Eksempel på beviser udvalgt af agenterne. Kredit:Perez et al.
-
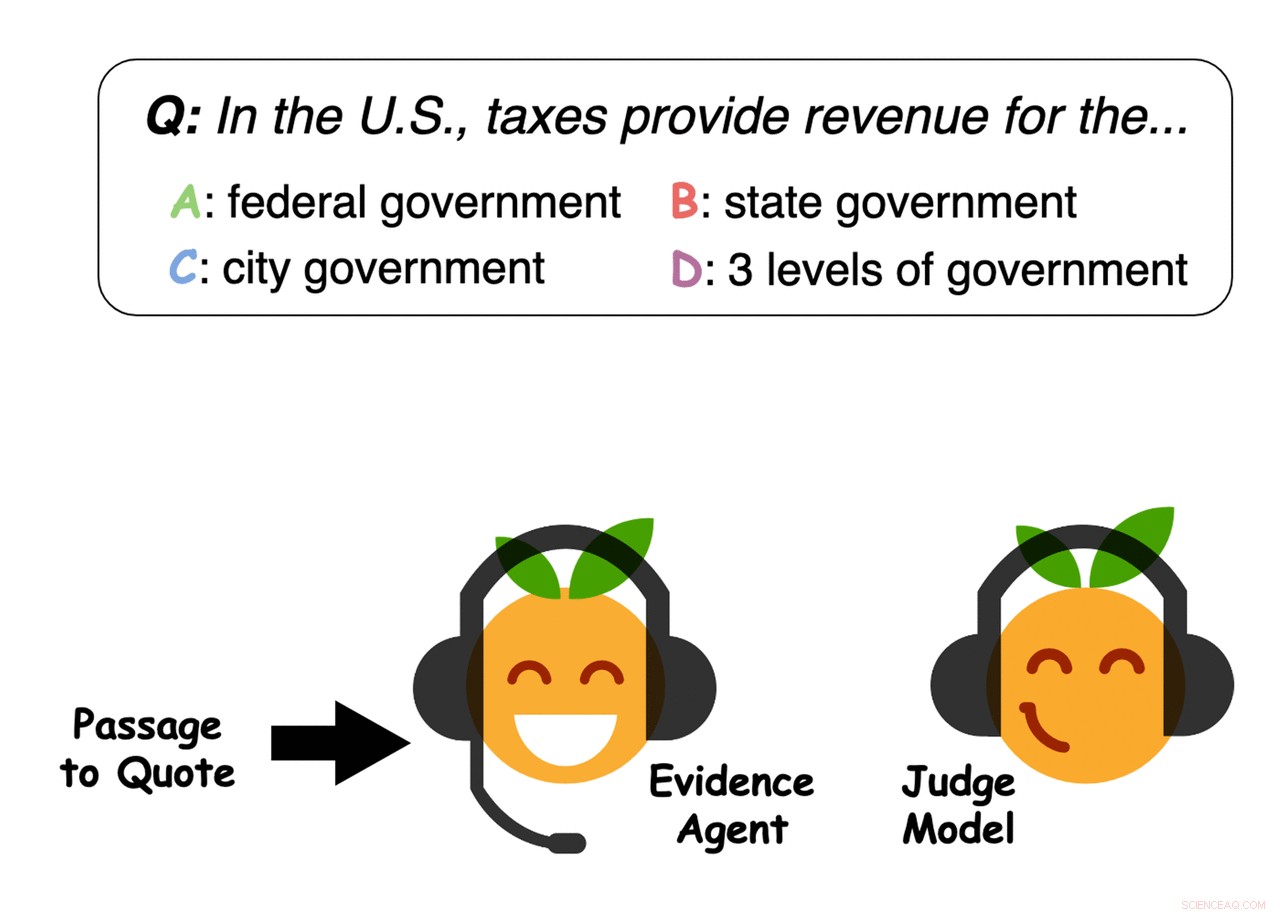
Kredit:Perez et al.
-

Eksempel på beviser udvalgt af agenterne. Kredit:Perez et al.
-
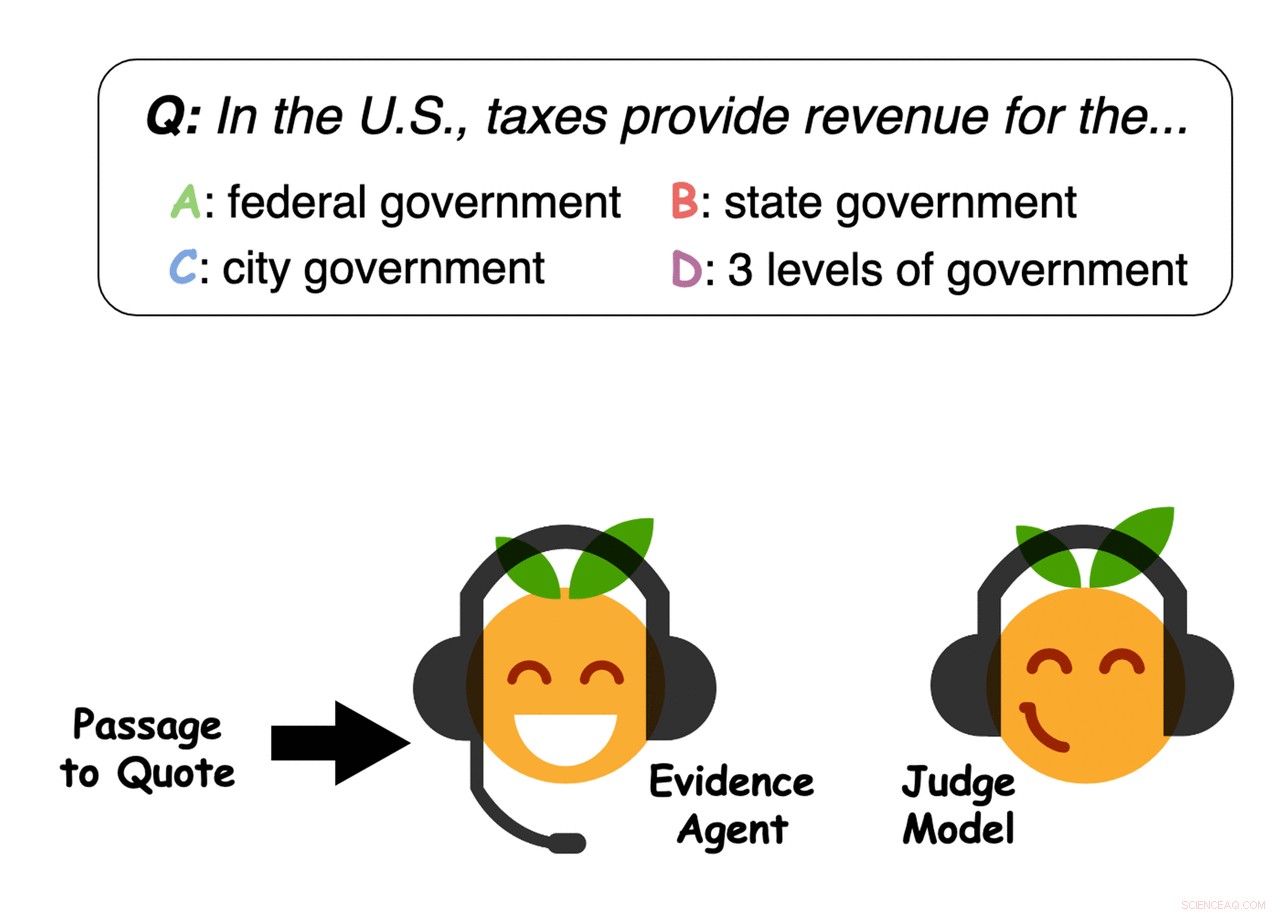
Bevisagenter citerer sætninger fra passagen for at overbevise en dommermodel, der besvarer spørgsmål, om et svar. Kredit:Perez et al.
"Fra et praktisk synspunkt, at finde beviser er nyttigt, " sagde Perez. "Folk kan besvare spørgsmål om lange artikler blot ved at læse vores systems beviser for hvert muligt svar. Derfor, generelt, ved automatisk at finde beviser, et system som vores kan potentielt hjælpe folk med at udvikle informerede meninger hurtigere."
Perez og hans kolleger fandt ud af, at deres tilgang til at indsamle beviser forbedrede spørgsmålsbesvarelsen væsentligt, giver mennesker mulighed for at svare korrekt på spørgsmål baseret på cirka 20 procent af en tekstpassage, som blev valgt af en maskinlæringsagent. Ud over, deres tilgang gjorde det muligt for QA-modeller at identificere svar på forespørgsler mere effektivt, generalisere bedre til længere passager og sværere spørgsmål.
I fremtiden, den tilgang, som dette team af forskere har udtænkt, og de observationer, de har indsamlet, kunne informere udviklingen af mere effektive og pålidelige QA maskinlæringsværktøjer. For nylig, Perez skrev også et blogindlæg på Medium, der forklarer ideerne præsenteret i papiret mere i dybden.
"At finde beviser er et første skridt mod modeller, der debatterer, " sagde Perez. "Sammenlignet med at finde beviser, debat er en endnu mere udtryksfuld måde at støtte en holdning på. At debattere kræver ikke kun at citere eksterne beviser, men også at konstruere dine egne argumenter – generere ny tekst. Jeg er interesseret i at træne modeller til at generere nye argumenter, samtidig med at det sikres, at den genererede tekst er sand og faktuelt korrekt."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Er vi nået til Peak Car?Myldretiden i Vancouver, B.C. Har Nordamerika nået Peak Car? Kredit:StoneMonkeyswk/Shutterstock.com General Motors har annonceret, at de lukker fem produktionsfaciliteter og dræber seks køretøjspl
Er vi nået til Peak Car?Myldretiden i Vancouver, B.C. Har Nordamerika nået Peak Car? Kredit:StoneMonkeyswk/Shutterstock.com General Motors har annonceret, at de lukker fem produktionsfaciliteter og dræber seks køretøjspl -
 Et nyt molekylært programmeringssprog:CRN++Euklids algoritme og hvordan den vil blive skrevet i CRN++. Kredit:Vasic et al. Syntetisk biologi er et relativt nyt forskningsområde, som kan påvirke en række områder betydeligt, herunder biologi
Et nyt molekylært programmeringssprog:CRN++Euklids algoritme og hvordan den vil blive skrevet i CRN++. Kredit:Vasic et al. Syntetisk biologi er et relativt nyt forskningsområde, som kan påvirke en række områder betydeligt, herunder biologi -
 Fagforeninger står over for hårde veje i Silicon ValleyMedarbejdere i teknologivirksomheder og startups flytter ofte ofte og får en række frynsegoder på arbejdspladsen, men aktivister siger, at der ikke desto mindre er stigende interesse for fagforeninger
Fagforeninger står over for hårde veje i Silicon ValleyMedarbejdere i teknologivirksomheder og startups flytter ofte ofte og får en række frynsegoder på arbejdspladsen, men aktivister siger, at der ikke desto mindre er stigende interesse for fagforeninger -
 Hvorfor skal vi alle klippe Facebook-snoren – eller skal vi det?Et nyt kunstig intelligens-værktøj, der er skabt til at hjælpe med at identificere visse former for stofmisbrug baseret på en hjemløs ungdoms Facebook-opslag, kunne give hjemløse krisecentre vital inf
Hvorfor skal vi alle klippe Facebook-snoren – eller skal vi det?Et nyt kunstig intelligens-værktøj, der er skabt til at hjælpe med at identificere visse former for stofmisbrug baseret på en hjemløs ungdoms Facebook-opslag, kunne give hjemløse krisecentre vital inf
- Et nyt system optimerer elektrisk transmission fra havvindmølleparker
- Brug af grafen og små dråber til at opdage mavekræftfremkaldende bakterier
- One night brand:Sexede snaps fører til rene køb
- Industri og forkæmpere sparrer om S.Afrikas kulstofafgift
- Forskere løser linkopdagelsesproblem for terahertz-datanetværk
- Hvilke typer metal er tiltrukket af magneter?