


Hvordan computerlingvistik hjælper med at forstå, hvordan sprog fungerer
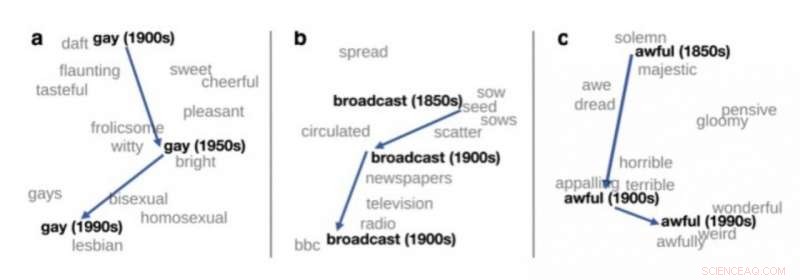
Todimensionelt syn på ændringen i betydning af tre engelske ord, taget fra Hamilton et al. (2016). Kredit:upf
Fordelingssemantik opnår repræsentationer af ordenes betydning ved at behandle tusindvis af tekster og uddrage generaliseringer ved hjælp af beregningsalgoritmer. På trods af populariteten af distributionssemantik inden for områder som computerlingvistik og kognitiv videnskab, dens indvirkning på teoretisk lingvistik har hidtil været meget begrænset.
Forskning af Gemma Boleda, leder af forskergruppen Computational Linguistics and Language Theory (COLT) og forskningsprofessor i ICREA ved Institut for Oversættelses- og Sprogvidenskab ved UPF, offentliggjort i tidsskriftet Årlig gennemgang af lingvistik , giver en kritisk gennemgang af de mange tilgængelige undersøgelser om distributionssemantik, lægge særlig vægt på de resultater, der er relevante for teoretisk lingvistik. Specifikt er der tre områder:semantisk forandring, polysemi og sammensætning, og grammatik-semantik-grænsefladen.
Gemma Boledas forskning søger at forbinde teoretiske og beregningsmæssige tilgange for at fremme i den kollektive viden om, hvordan sprog fungerer. En af de metoder, hun har forsket meget i, er distributionssemantik, som gør det muligt at opnå repræsentationer af ord automatisk. Disse repræsentationer har vist sig at afspejle væsentlige sproglige egenskaber, såsom hvordan to ord ligner hinanden:en person vil fortælle dig, at "hund" og "hvalp" er meget ens, og dog ligner "hund" og "demokrati" næppe ens overhovedet; distributionssemantik vil sige det samme, takket være, at det fremkalder sproglige egenskaber baseret på tekster skrevet af mennesker. Derfor, distributionssemantik giver radikalt empiriske repræsentationer.
Fordelingssemantik gør det muligt at analysere brugen af ord og udviklingen af deres betydning
Distributionssemantik giver en attraktiv, komplementære rammer til andre, mere traditionelle metoder, ikke kun fordi det er radikalt empirisk, men også fordi det giver multidimensionelle repræsentationer:to ord kan sammenlignes på én betydningsdimension ("pizza" og "pasta" er typer mad), eller på en anden ("pizza" og "hjul" er runde). At repræsentere alle aspekter af betydning, flerdimensionelle repræsentationer er nødvendige. Distributionssemantik kan indfange de almindelige anvendelser af to ord, samt deres differentierende faktorer.
En af de vigtige anvendelser af distributionssemantik i teoretisk lingvistik er påvisningen af ændringer i mening. Hvis sprogdata fra forskellige perioder behandles, bøger på engelsk fra 1900, 1950 og 1990, distributionssemantik kan bruges til automatisk at detektere nogle ords ændring i betydning. For eksempel, ordet "gay" på engelsk i begyndelsen af forrige århundrede betød "happy" og er blevet brugt i stigende grad til at betyde "homoseksuel".
Aspekter af forskning i distributionssemantik, der bidrager til sprogteori
Fra analysen af de undersøgte værker, Boleda konkluderer, at der er tilstrækkelig evidens for, at de solide resultater af distributionssemantik kan importeres direkte til forskning i teoretisk lingvistik.
"Der er mindst fire aspekter af forskning i distributionssemantik, der kan bidrage til sprogteori. Det første aspekt er undersøgende:distributionsrepræsentationer kan bruges til at udforske data i stor skala, for eksempel ved at undersøge ords lighed. Den anden er som et værktøj til at identificere specifikke tilfælde af sproglige fænomener. For eksempel, ord kan identificeres, hvis betydning har ændret sig, når man sammenligner repræsentationerne opnået fra tekster fra forskellige perioder. Den tredje er som en testbænk:evaluering af forskellige sproglige hypoteser i fordelingsmæssige termer. Den fjerde og sværeste er opdagelsen af nye sproglige fænomener eller relevante teoretiske tendenser i dataene, " forklarer forfatteren i sit arbejde.
 Varme artikler
Varme artikler
-
 Havstigningen forventes at true 13, 000 arkæologiske steder i det sydøstlige USATitusindvis af kendte arkæologiske steder er truet af havniveaustigning i sydøst, og langt mere ukendt og uoptaget i øjeblikket, som vist her ved lav rumlig opløsning. Kredit:Anderson et al., 2017
Havstigningen forventes at true 13, 000 arkæologiske steder i det sydøstlige USATitusindvis af kendte arkæologiske steder er truet af havniveaustigning i sydøst, og langt mere ukendt og uoptaget i øjeblikket, som vist her ved lav rumlig opløsning. Kredit:Anderson et al., 2017 -
 Hvorfor arbejder folk? Respekt overtrumf penge i Sydafrikas casestudieForhold på arbejdspladsen påvirker medarbejdernes beslutninger om at blive i job. Kredit:Shutterstock/LongJon I Sydafrika, mere end 50% af voksne i den erhvervsaktive alder har ikke job. Men still
Hvorfor arbejder folk? Respekt overtrumf penge i Sydafrikas casestudieForhold på arbejdspladsen påvirker medarbejdernes beslutninger om at blive i job. Kredit:Shutterstock/LongJon I Sydafrika, mere end 50% af voksne i den erhvervsaktive alder har ikke job. Men still -
 Hvorfor folk går i gæld:Pengene er ikke rigtig deresForskere fandt ud af, at folk opfatter kreditkortgæld og traditionelle banklån forskelligt, selvom begge kræver at låne penge. Kredit:iStock/PeopleImages I 2019, USAs forbrugergæld nåede et rekord
Hvorfor folk går i gæld:Pengene er ikke rigtig deresForskere fandt ud af, at folk opfatter kreditkortgæld og traditionelle banklån forskelligt, selvom begge kræver at låne penge. Kredit:iStock/PeopleImages I 2019, USAs forbrugergæld nåede et rekord -
 Kønsbias på arbejdspladsen starter med kommunikation under rekrutteringKredit:Pixabay/CC0 Public Domain Firs procent af jobs kommunikeres til folk uformelt, og denne kommunikation er ofte fyldt med kønsbias, give en kvindelig (versus mandlig) kandidat en mindre posit
Kønsbias på arbejdspladsen starter med kommunikation under rekrutteringKredit:Pixabay/CC0 Public Domain Firs procent af jobs kommunikeres til folk uformelt, og denne kommunikation er ofte fyldt med kønsbias, give en kvindelig (versus mandlig) kandidat en mindre posit
- Ingen joke:Det er sværere at bruge humor i klassen, når læringen er fjern
- Forskere udvikler verdens tyndeste elektriske generator
- Hvorfor er verdens største losseplads i Stillehavet?
- Airbus sælger 65 jetfly til SMBC Aviation Capital
- Konstruerede vådområder er den bedste beskyttelse for landbrugsafstrømning i vandveje
- Uber tilbyder gratis måltider, rabat på kørsel til sundhedspersonale