


Håndtering af Sydafrikas kræftrapporteringsforsinkelse med maskinlæring

Waheeda Saib. Kredit:IBM
Kræftregistre rummer vitale datasæt, holdes tæt krypteret, indeholdende demografiske oplysninger, medicinsk historie, diagnostik og terapi. Onkologer og sundhedsembedsmænd får adgang til dataene for at forstå de diagnosticerede kræfttilfælde og forekomstrater nationalt. Det ultimative mål er at bruge disse data til at informere folkesundhedsplanlægning og interventionsprogrammer. Selvom realtidsopdateringer ikke er praktiske, Forsinkelser på flere år gør det udfordrende for embedsmænd at forstå virkningen af kræft i landet og allokere ressourcer i overensstemmelse hermed.
Ustrukturerede patologirapporter indeholder tumorspecifikke data og er hovedkilden til information indsamlet af cancerregistre. Menneskelige eksperter mærker patologirapporterne ved hjælp af International Classification of Disease for Oncology (ICD-O) koder, der spænder over 42 forskellige kræfttyper. Kombinationen af manuelle processer og omfanget af årlige indberetninger fører til fire års forsinkelse for landet. Sammenlignet med, der er næsten to års forsinkelse i USA.
I 2016 da vi indviede vores nye IBM Research laboratorium i Johannesburg, vi påtog os denne udfordring og rapporterer vores første lovende resultater på Health Day på KDD Data Science Conference i London i denne måned.
Vores mål fra begyndelsen var at anvende dyb læring til at automatisere mærkning af kræftpatologirapporter for at fremskynde rapporteringsprocessen. Arbejder med National Cancer Registry i Sydafrika, vi brugte 2, 201 afidentificeret, fritekstpatologirapporter, og jeg er stolt over at kunne rapportere, at vores papir viser 74 procents nøjagtighed – en forbedring i forhold til nuværende benchmarkmodeller. Vi tror på, at vi kan opnå 95 procent nøjagtighed med flere data.
Vi anvendte hierarkisk klassifikation med foldede neurale netværk, selvom dette ikke var vores første valg. Vi begyndte oprindeligt at udforske multiklasse- og binære konvolutionelle neurale netværksmodeller, men resultaterne var ikke lovende, og jeg holdt næsten op i frustration. Til sidst, med råd og støtte fra mine kolleger, vi ryddede op i teksten, forfinet funktionskonstruktionsprocessen og forbedret den til 60 procent. Dette resultat var en forbedring, men vi vidste, at vi havde brug for 90-95 procent for at gøre det troværdigt nok for den virkelige verden.
Efter mere forskning og udforskning, vi tænkte på at reducere kompleksiteten af multiklasseproblemet, hvilket førte os til at skabe en state-of-the-art hierarkisk deep learning klassifikationsmetode baseret på den hierarkiske struktur af det onkologiske ICD-O kodningssystem. Dermed, vi brugte en kombineret tilgang til at identificere klassehierarki og validere det ved hjælp af ekspertviden for at opnå bedre ydeevne end en flad multiklassemodel til klassificering af fritekstpatologirapporter.
Vores arbejde er naturligvis ikke færdigt endnu; vi skal nå over 95 procents nøjagtighed, og vi tror, det er muligt med flere data, som vil blive leveret af vores partnere i Det Nationale Kræftregister. Når vi først har fået dette, vi tror, at Sydafrika kan være det bedste i verden med hensyn til kræftrapportering, hvilket er vigtigt, især fordi det er blevet rapporteret, at mit land vil opleve en stigning på 78 procent i kræft i 2030.
Denne historie er genudgivet med tilladelse fra IBM Research. Læs den originale historie her.
Sidste artikelFisker har design på solid state batteri gennembrud
Næste artikelVolkswagen i strid med mexicanske landmænd
 Varme artikler
Varme artikler
-
 Facebook øger formatet for historier, nu åben for annoncerFacebook øger sin indsats for at promovere sit historier -format, visuelle beskeder, der ligner dem på Snapchat Facebook sagde onsdag, at det nu har 300 millioner daglige brugere af historier, et
Facebook øger formatet for historier, nu åben for annoncerFacebook øger sin indsats for at promovere sit historier -format, visuelle beskeder, der ligner dem på Snapchat Facebook sagde onsdag, at det nu har 300 millioner daglige brugere af historier, et -
 Kunstig intelligens skinner lys på det mørke netFor at matche brugere fra forskellige fora, som sandsynligvis er den samme person, en algoritme beregner ligheder i profiler, såsom deres brugernavne; i indhold, såsom lignende fraseringer; og i deres
Kunstig intelligens skinner lys på det mørke netFor at matche brugere fra forskellige fora, som sandsynligvis er den samme person, en algoritme beregner ligheder i profiler, såsom deres brugernavne; i indhold, såsom lignende fraseringer; og i deres -
 Argentinsk ubådsvrag fundet et år efter forsvindenDen argentinske flådeubåd ARA San Juan lagde til i Buenos Aires i 2014 Det knuste vrag af en argentinsk ubåd er blevet lokaliseret et år efter, at det forsvandt i Atlanterhavets dybder med 44 besæ
Argentinsk ubådsvrag fundet et år efter forsvindenDen argentinske flådeubåd ARA San Juan lagde til i Buenos Aires i 2014 Det knuste vrag af en argentinsk ubåd er blevet lokaliseret et år efter, at det forsvandt i Atlanterhavets dybder med 44 besæ -
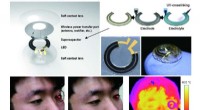 En kontaktlinse, der kan vise, når blodsukkerniveauet er højtOversigt over den trådløst genopladelige smarte kontaktlinse. Kredit:Jang-Ung Park, Yonsei Universitet Et team af forskere tilknyttet flere institutioner i Republikken Korea har udviklet en kontak
En kontaktlinse, der kan vise, når blodsukkerniveauet er højtOversigt over den trådløst genopladelige smarte kontaktlinse. Kredit:Jang-Ung Park, Yonsei Universitet Et team af forskere tilknyttet flere institutioner i Republikken Korea har udviklet en kontak
- IAU godkender 86 nye stjernenavne fra hele verden
- Udforskning af årsagerne til vedvarende korruption
- NASA udvælger forslag til yderligere at studere rummets grundlæggende karakter
- Sådan bestemmer du Specifik Gravity
- Pop-up-robotter muliggør ekstrem terrænvidenskab
- Jeg tror ikke, jeg kan klare mig økonomisk:Folk udskyder forældreskabet på grund af stramninger