


Semantisk cache til AI-aktiveret billedanalyse
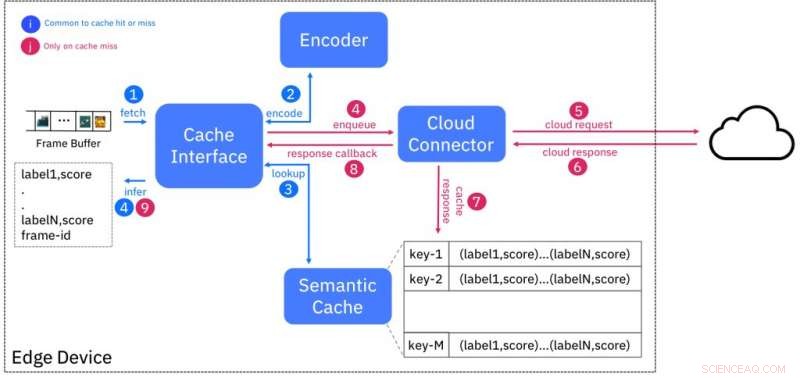
Blokdiagram over semantisk cachetjeneste. Kredit:IBM
Tilgængeligheden af høj opløsning, billige sensorer har eksponentielt øget mængden af data, der produceres, som kunne overvælde det eksisterende internet. Dette har ført til behovet for computerkapacitet til at behandle dataene tæt på, hvor de genereres, i kanterne af netværket, i stedet for at sende det til cloud -datacentre. Edge computing, som dette er kendt, reducerer ikke kun belastningen af båndbredde, men reducerer også forsinkelse ved at opnå intelligens fra rådata. Imidlertid, tilgængeligheden af ressourcer på kanten er begrænset på grund af manglen på stordriftsfordele, der gør cloud-infrastruktur omkostningseffektiv at administrere og tilbyde.
Potentialet ved edge computing er ingen steder mere indlysende end med videoanalyse. High-definition (1080p) videokameraer bliver almindelige i domæner som overvågning og, afhængigt af billedhastigheden og datakomprimering, kan producere 4-12 megabit data i sekundet. Nyere 4K -opløsningskameraer producerer rådata i størrelsesordenen gigabit per sekund. Kravet om realtidsindsigt i sådanne videostrømme driver brugen af AI-teknikker såsom dybe neurale netværk til opgaver, herunder klassificering, genkendelse og ekstraktion af objekter, og detektering af anomali.
I vores Hot Edge 2018-konferencepapir "Shadow Puppets:Cloud-level Accurate AI Inference at the Speed and Economy of Edge, "vores team hos IBM Research - Irland evaluerede eksperimentelt udførelsen af en sådan AI -arbejdsbyrde, objektklassificering, ved hjælp af kommercielt tilgængelige cloud-hostede tjenester. Det bedste resultat, vi kunne sikre, var en klassificeringsoutput på 2 billeder i sekundet, som er langt under standardvideoproduktionshastigheden på 24 billeder i sekundet. Udførelse af et lignende eksperiment på en repræsentativ kant -enhed (NVIDIA Jetson TK1) opnåede latenstidskravene, men brugte de fleste ressourcer, der var tilgængelige på enheden i denne proces.
Vi bryder denne dualitet ved at foreslå den semantiske cache, en tilgang, der kombinerer den lave latens for kantimplementeringer med de næsten uendelige ressourcer, der er tilgængelige i skyen. Vi bruger den velkendte cacheteknik til at maskere latenstid ved at udføre AI-slutning for et bestemt input (f.eks. Videoramme) i skyen og lagre resultaterne på kanten mod et "fingeraftryk", eller en hash -kode, baseret på funktioner hentet fra input.
Denne ordning er designet således, at input, der er semantisk ens (f.eks. Tilhører samme klasse), vil have fingeraftryk, der er "tæt på" hinanden, efter et eller andet afstandsmål. Figur 1 viser design af cachen. Koderen opretter fingeraftryk på en inputvideoramme og søger cachen efter fingeraftryk inden for en bestemt afstand. Hvis der er et match, derefter leveres slutresultaterne fra cachen, dermed undgås behovet for at forespørge AI -tjenesten, der kører i skyen.
Vi finder fingeraftrykkene analoge med skyggedukker, todimensionelle fremskrivninger af figurer på en skærm skabt af et lys i baggrunden. Enhver, der har brugt sine fingre til at skabe skyggedukker, vil bevidne, at fraværet af detaljer i disse figurer ikke begrænser deres evne til at være grundlaget for en god historiefortælling. Fingeraftrykkene er fremskrivninger af det faktiske input, der kan bruges til rige AI -applikationer, selv i mangel af originale detaljer.
Vi har udviklet et komplet bevis på konceptimplementering af den semantiske cache, efter en "som en service" design tilgang, og udsætte tjenesten for kant -enhed/gateway -brugere via en REST -grænseflade. Vores evalueringer på en række forskellige kantenheder (Raspberry Pi 3/NVIDIA Jetson TK1/TX1/TX2) har vist, at inferensens latens er reduceret med 3 gange og båndbreddeforbruget med mindst 50 procent sammenlignet med en sky- eneste løsning.
Tidlig evaluering af en første prototypeimplementering af vores tilgang viser sit potentiale. Vi fortsætter med at modne den indledende tilgang, prioriterer at eksperimentere med alternative kodningsteknikker til forbedret præcision, samtidig med at evalueringen udvides til at omfatte yderligere datasæt og AI -opgaver.
Vi forestiller os, at denne teknologi skal have applikationer i detailhandel, forudsigelig vedligeholdelse af industrielle faciliteter, og videoovervågning, blandt andre. For eksempel, den semantiske cache kunne bruges til at gemme fingeraftryk af produktbilleder ved kassen. Dette kan bruges til at forhindre tab af butikker på grund af tyveri eller fejlscanning. Vores tilgang fungerer som et eksempel på problemfrit skift mellem cloud- og edge-tjenester for at levere de bedste AI-løsninger på kanten.
Denne historie er genudgivet med tilladelse fra IBM Research. Læs den originale historie her.
 Varme artikler
Varme artikler
-
 Yahoo Japan, Linje for at fusionere forretning til dannelse af en onlinegigantDenne fredag, 15. nov., 2019, billedet viser logfiler fra Yahoo Japan og Line Corp. i Tokyo. Onlinetjenesterne annoncerede mandag, 18. nov., 2019, de smelter sammen. Sammenlægningen i et joint venture
Yahoo Japan, Linje for at fusionere forretning til dannelse af en onlinegigantDenne fredag, 15. nov., 2019, billedet viser logfiler fra Yahoo Japan og Line Corp. i Tokyo. Onlinetjenesterne annoncerede mandag, 18. nov., 2019, de smelter sammen. Sammenlægningen i et joint venture -
 Selfies – hvorfor vi elsker (og hader) demVi mennesker, har en lang historie med at blive tiltrukket af billeder, at kommunikere visuelt, og at blive fortryllet med (vores egne) ansigter. Selfies er bare en anden måde at repræsentere os selv
Selfies – hvorfor vi elsker (og hader) demVi mennesker, har en lang historie med at blive tiltrukket af billeder, at kommunikere visuelt, og at blive fortryllet med (vores egne) ansigter. Selfies er bare en anden måde at repræsentere os selv -
 Maskinindlæring forudsiger blackouts forårsaget af stormeKredit:CC0 Public Domain Tordenvejr er almindeligt overalt i verden om sommeren. Samt forkælelse af eftermiddage i parken, lyn, regn og stærk vind kan beskadige elnet og forårsage strømafbrydelse.
Maskinindlæring forudsiger blackouts forårsaget af stormeKredit:CC0 Public Domain Tordenvejr er almindeligt overalt i verden om sommeren. Samt forkælelse af eftermiddage i parken, lyn, regn og stærk vind kan beskadige elnet og forårsage strømafbrydelse. -
 Kina undersøger formodet kundedatalæk hos Accor-partnerHuazhu, en af Kinas største hotelejere, sagde, at frigivelsen af dataene havde forårsaget en ond indvirkning, og at det var i gang med en intern undersøgelse Shanghais politi sagde, at de unde
Kina undersøger formodet kundedatalæk hos Accor-partnerHuazhu, en af Kinas største hotelejere, sagde, at frigivelsen af dataene havde forårsaget en ond indvirkning, og at det var i gang med en intern undersøgelse Shanghais politi sagde, at de unde
- En spin-bølge-detektivhistorie:Forskere bekræfter overraskende adfærd i en 2-D-magnet
- DNA-beviser sætter næsehornkrybskytter bag tremmer, viser undersøgelse
- Metalliske drivere til Alzheimers sygdom
- Klimaændringer forbundet med store ændringer i oversvømmelser i hele Europa
- Cybermobning blandt teenagere:Forskning viser, at onlinemisbrug og skolemobning ofte er forbundet
- Louisiana håber at bekæmpe kysterosion ved at efterligne naturen