


En dyb læringsteknik til at generere læbesynkronisering i realtid til live 2D-animation
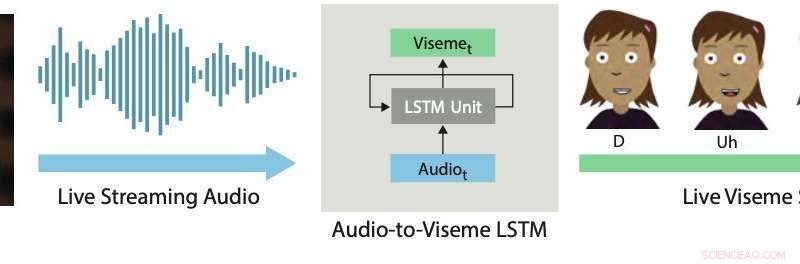
Læbesynkronisering i realtid. Vores deep learning -tilgang bruger en LSTM til at konvertere live streaming -lyd til diskrete visemer til 2D -tegn. Kredit:Aneja &Li.
Live 2-D-animation er en ret ny og kraftfuld kommunikationsform, der giver menneskelige kunstnere mulighed for at kontrollere tegneseriefigurer i realtid, mens de interagerer og improviserer med andre skuespillere eller medlemmer af et publikum. Nylige eksempler omfatter Stephen Colbert, der interviewer tegneseriegæster på Det sene show , Homer besvarer direkte telefon-ind-spørgsmål fra seere under et segment af The Simpsons , Archer taler med et live publikum på ComicCon, og Disneys stjerner Stjerne vs. Ondskabens kræfter og Min lille pony vært for live chat -sessioner med fans via YouTube eller Facebook Live.
At producere realistiske og effektive live 2D-animationer kræver brug af interaktive systemer, der automatisk kan transformere menneskelige præstationer til animationer i realtid. Et nøgleaspekt ved disse systemer er at opnå en god læbesynkronisering, hvilket i det væsentlige betyder, at animerede personers mund bevæger sig passende, når de taler, efterligner de bevægelser, der observeres i munden på kunstnere.
God læbesynkronisering kan gøre live 2D-animation mere overbevisende og kraftfuld, tillader animerede figurer at legemliggøre forestillingen mere realistisk. Omvendt dårlig læbesynkronisering bryder typisk illusionen om karakterer som live deltagere i en optræden eller dialog.
I et papir, der for nylig blev forudgivet den arXiv, to forskere ved Adobe Research og University of Washington introducerede et dybt læringsbaseret interaktivt system, der automatisk genererer levende læbesynkronisering for lagdelte 2D-animerede figurer. Systemet, de udviklede, bruger en lang korttidshukommelse (LSTM) model, en tilbagevendende neural netværksarkitektur (RNN) ofte anvendt til opgaver, der involverer klassificering eller behandling af data, samt at lave forudsigelser.
"Da tale er den dominerende komponent i næsten hver levende animation, vi mener, at det mest kritiske problem at løse i dette domæne er live lip sync, hvilket indebærer at omdanne en skuespillers tale til tilsvarende mundbevægelser (dvs. viseme-sekvens) i den animerede figur. I dette arbejde, vi fokuserer på at skabe højkvalitets lip sync til live 2-D animation, " Wilmot Li og Deepali Aneja, de to forskere, der har udført forskningen, fortalte TechXplore via e-mail.
Li er ledende videnskabsmand hos Adobe Research med en ph.d. i datalogi, som har udført omfattende forskning med fokus på emner i krydsfeltet mellem computergrafik og menneske-computer interaktion. Aneja, på den anden side, er i øjeblikket ved at færdiggøre en ph.d. i datalogi ved University of Washington, hvor hun er en del af Graphics and Imaging Lab.
Systemet udviklet af Li og Aneja bruger en simpel LSTM-model til at konvertere streaming lydinput til en tilsvarende viseme-sekvens med 24 billeder i sekundet, med mindre end 200 millisekunders latenstid. Med andre ord, deres system tillader en animeret karakters læber at bevæge sig på samme måde som en menneskelig brugers læber, der taler i realtid, med mindre end 200 millisekunders forsinkelse mellem stemmen og læbebevægelsen.
"I dette arbejde, vi yder to bidrag – at identificere den passende funktionsrepræsentation og netværkskonfiguration for at opnå avancerede resultater for live 2-D læbesynkronisering og udtænke en ny forstærkningsmetode til indsamling af træningsdata til modellen, ”Li og Aneja forklarede.
"Til håndforfatter lip sync, professionelle animatorer træffer stilistiske beslutninger om det specifikke valg af visemer og timingen og antallet af overgange. Som resultat, træning af en enkelt 'generel' model er usandsynligt nok til de fleste applikationer, sagde Li og Aneja. Desuden, Det kan være både dyrt og tidskrævende at indhente mærkede lip sync-data for at træne deep learning-modeller. Professionelle animatorer kan bruge fem til syv timers arbejde pr. minut af tale til at håndforfatte viseme-sekvenser. Er opmærksom på disse begrænsninger, Li og Aneja udviklede en metode, der kan generere træningsdata hurtigere og mere effektivt.
For at træne deres LSTM -model mere effektivt, Li og Aneja introducerede en ny teknik, der forstærker håndforfattede træningsdata ved hjælp af lyd-tidsforskydning. Denne dataforøgelsesprocedure opnåede god læbesynkronisering, selv når de trænede deres model på et lille mærket datasæt.
For at evaluere effektiviteten af deres interaktive system til at producere læbesynkronisering i realtid, forskerne bad menneskelige seere om at vurdere kvaliteten af live-animationer drevet af deres model med dem, der blev produceret ved hjælp af kommercielle 2-D-animationsværktøjer. De fandt ud af, at de fleste seere foretrak læbesynkroniseringen, der blev genereret af deres tilgang, frem for den, der blev produceret af andre teknikker.
"Vi undersøgte også afvejningen mellem læbesynkroniseringskvalitet og mængden af træningsdata, og vi fandt ud af, at vores dataforøgelsesmetode markant forbedrer modellens output, " sagde Li og Aneja. "Generelt, vi kan producere rimelige resultater med kun 15 minutters håndforfattede læbesynkroniseringsdata."
Interessant nok, forskerne fandt ud af, at deres LSTM-model kan erhverve forskellige læbesynkroniseringsstile baseret på de data, den er trænet på, samtidig med at den generaliserer godt på tværs af en bred vifte af højttalere. Imponeret over de opmuntrende resultater opnået af modellen, Adobe besluttede at integrere en version af det i sin Adobe Character Animator-software, udgivet i efteråret 2018.
"Nøjagtig, læbesynkronisering med lav latens er vigtig for næsten alle live animationsindstillinger, og vores eksperimenter med menneskelig vurdering viser, at vores teknik forbedrer de eksisterende topmoderne 2-D-lip-sync-motorer, hvoraf de fleste kræver offline behandling, " sagde Li og Aneja. Således, forskerne mener, at deres arbejde har umiddelbare praktiske implikationer for både live og ikke-live 2-D animationsproduktion. Forskerne er ikke klar over tidligere 2-D lip sync-arbejde med tilsvarende omfattende sammenligninger med kommercielle værktøjer.
I deres nylige undersøgelse, Li og Aneja var i stand til at løse nogle af de vigtigste tekniske udfordringer forbundet med udviklingen af teknikker til live 2-D animation. Først, de demonstrerede en ny metode til at kode kunstneriske regler for 2-D læbesynkronisering ved hjælp af RNN'er, som kan forbedres yderligere i fremtiden.
Forskerne mener, at der er mange flere muligheder for at anvende moderne maskinlæringsteknikker til at forbedre 2D-animationsarbejdsgange. "Så langt, en udfordring har været manglen på træningsdata, som er dyrt at samle. Imidlertid, som vi viser i dette værk, der kan være måder at udnytte strukturerede data og automatiske redigeringsalgoritmer (f.eks. dynamisk tidsforskydning) for at maksimere nytten af håndlavede animationsdata, " sagde Li og Aneja.
Selvom den dataforøgelsesstrategi, som forskerne har foreslået, kan reducere træningsdatakravene betydeligt for modeller designet til at producere læbesynkronisering i realtid, Håndanimering af nok lipsync-indhold til at træne nye modeller kræver stadig betydeligt arbejde og kræfter. Ifølge Li og Aneja, imidlertid, Det kan være unødvendigt at genoptræne en hel model fra bunden for hver ny lip sync-stil, den støder på.
Forskerne er interesserede i at udforske finjusteringsstrategier, der kan give animatorer mulighed for at tilpasse modellen til forskellige stilarter med en meget mindre mængde brugerinput. "En relateret idé er direkte at lære en læbesynkroniseringsmodel, der eksplicit inkluderer justerbare stilistiske parametre. Selvom dette kan kræve et meget større træningsdatasæt, den potentielle fordel er en model, der er generel nok til at understøtte en række læbesynkroniseringsstile uden yderligere træning, " sagde forskerne.
Interessant nok, i deres eksperimenter, forskerne observerede, at det simple krydsentropitab, de brugte til at træne deres model, ikke nøjagtigt afspejlede de mest relevante perceptuelle forskelle mellem læbesynkroniseringssekvenser. Mere specifikt, de fandt ud af, at visse uoverensstemmelser (f.eks. mangler en overgang eller udskiftning af en lukket mund viseme med en åben mund viseme) er meget mere indlysende end andre. "Vi tror, at design eller læring af et perceptuelt baseret tab i fremtidig forskning kan føre til forbedringer i den resulterende model, " sagde Li og Aneja.
© 2019 Science X Network
Sidste artikelHvordan strikning vandt krigen
Næste artikelHistorisk Disney+ streaming-lancering skæmmet af fejl
 Varme artikler
Varme artikler
-
 Banker, Bitcoin, obligationsfonde:Hvor er dine penge sikre i en tid med cyberangreb?Kredit:CC0 Public Domain I næsten et årti, John Luksic brugte en Bitcoin-børs til at investere penge i kryptovalutaer, forsøgte at bygge et redeæg, mens han passede sine forældre i Saginaw, Michig
Banker, Bitcoin, obligationsfonde:Hvor er dine penge sikre i en tid med cyberangreb?Kredit:CC0 Public Domain I næsten et årti, John Luksic brugte en Bitcoin-børs til at investere penge i kryptovalutaer, forsøgte at bygge et redeæg, mens han passede sine forældre i Saginaw, Michig -
 Spørgsmål og svar:Trump, posthuset og AmazonI denne 14. dec. 2017, fil foto, kasser til sorteret post er stablet på hovedpostkontoret i Omaha, Neb. En taskforce vil studere det amerikanske postvæsen i henhold til en bekendtgørelse fra præsident
Spørgsmål og svar:Trump, posthuset og AmazonI denne 14. dec. 2017, fil foto, kasser til sorteret post er stablet på hovedpostkontoret i Omaha, Neb. En taskforce vil studere det amerikanske postvæsen i henhold til en bekendtgørelse fra præsident -
 1,5 mia. følsomme dokumenter på åbent internet:forskereForskere siger, at enorme mængder af følsomme filer på det åbne internet gør det lettere for hackere og andre at stjæle data Omkring 1,5 milliarder følsomme onlinefiler, fra lønsedler til medicins
1,5 mia. følsomme dokumenter på åbent internet:forskereForskere siger, at enorme mængder af følsomme filer på det åbne internet gør det lettere for hackere og andre at stjæle data Omkring 1,5 milliarder følsomme onlinefiler, fra lønsedler til medicins -
 737 MAX-katastrofen skubber Boeing i krisetilstandBoeing blev kritiseret for at have undladt at reagere mere beslutsomt efter det andet dødbringende styrt på mindre end fem måneder med dets 737 MAX-fly Efter en anden luftkatastrofe, der involvere
737 MAX-katastrofen skubber Boeing i krisetilstandBoeing blev kritiseret for at have undladt at reagere mere beslutsomt efter det andet dødbringende styrt på mindre end fem måneder med dets 737 MAX-fly Efter en anden luftkatastrofe, der involvere
- Sådan testes et 9 Volt batteri
- Pas på dig selv:selvovervågningsstrategien for at holde supermarkedshandlende ærlige
- Forskere på Twitter:Prædiker for koret eller synger fra hustagene?
- Hvorfor COVID-19 misinformation spredte sig hurtigere end pandemi i begyndelsen af marts
- Strandet uden transit? Forskere siger, at 1 million canadiere lider af transportfattigdom
- Injicerbar hydrogel kan en dag føre til mere effektive vacciner