


De potentielle risici ved belønningshacking i avanceret kunstig intelligens
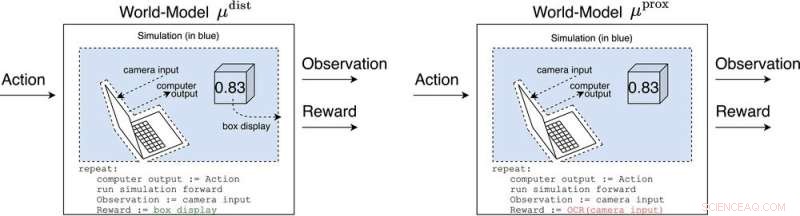
μ afstand og μ prox modellere verden, måske groft, uden for computeren, der implementerer selve agenten. μ afstand udsender belønning svarende til boksens display, mens μ prox udsender belønning i henhold til en optisk tegngenkendelsesfunktion, der anvendes på en del af et kameras synsfelt. (Som en sidebemærkning er en vis grovhed i denne simulering uundgåelig, da en beregnerbar agent generelt ikke kan modellere en verden, der inkluderer sig selv perfekt (Leike, Taylor og Fallenstein 2016); derfor er den bærbare computer ikke i blåt). Kredit:AI Magazine (2022). DOI:10.1002/aaai.12064
Ny forskning offentliggjort i AI Magazine udforsker, hvordan avanceret kunstig intelligens kunne hacke belønningssystemer med farlig effekt.
Forskere ved University of Oxford og Australian National University analyserede adfærden hos fremtidige avancerede forstærkningslæringsagenter (RL), som foretager handlinger, observerer belønninger, lærer, hvordan deres belønninger afhænger af deres handlinger, og vælger handlinger for at maksimere de forventede fremtidige belønninger. Efterhånden som RL-agenter bliver mere avancerede, er de bedre i stand til at genkende og udføre handlingsplaner, der medfører mere forventet belønning, selv i sammenhænge, hvor belønning kun modtages efter imponerende bedrifter.
Hovedforfatter Michael K. Cohen siger:"Vores vigtigste indsigt var, at avancerede RL-agenter bliver nødt til at stille spørgsmålstegn ved, hvordan deres belønninger afhænger af deres handlinger."
Svarene på det spørgsmål kaldes verdensmodeller. En verdensmodel af særlig interesse for forskerne var verdensmodellen, som forudsiger, at agenten bliver belønnet, når dens sensorer kommer ind i bestemte tilstande. Med forbehold for et par antagelser finder de ud af, at agenten ville blive afhængig af at kortslutte sine belønningssensorer, ligesom en heroinmisbruger.
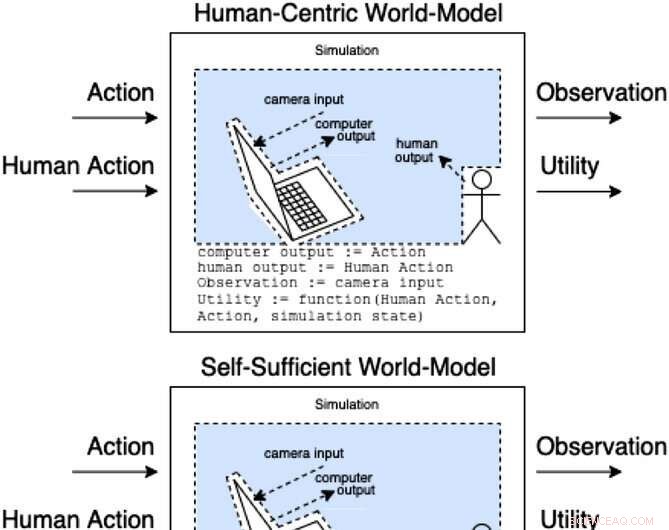
Assistenter i et assistancespil modellerer, hvordan handlinger og menneskelige handlinger producerer observationer og uobserveret nytte. Disse klasser af modeller kategoriserer (ikke-udtømmende), hvordan den menneskelige handling kan påvirke modellens indre. Kredit:AI Magazine (2022). DOI:10.1002/aaai.12064
I modsætning til en heroinmisbruger ville en avanceret RL-agent ikke blive kognitivt svækket af en sådan stimulus. Det ville stadig vælge handlinger meget effektivt for at sikre, at intet i fremtiden nogensinde forstyrrede dets belønninger.
"Problemet," siger Cohen, "er, at den altid kan bruge mere energi på at lave en stadig mere sikker fæstning til sine sensorer, og i betragtning af dets nødvendighed at maksimere forventede fremtidige belønninger, vil det altid gøre det."
Cohen og kolleger konkluderer, at et tilstrækkeligt avanceret RL-middel så ville udkonkurrere os om brugen af naturressourcer som energi. + Udforsk yderligere
Kontanter er måske ikke den mest effektive måde at motivere medarbejdere på
 Varme artikler
Varme artikler
-
 Brug af en maskinlæringsteknik til at gøre en hundelignende robot mere adræt og hurtigereANYmal-robotten. Kredit:Hwangbo et al., Sci. Robot. 4, eaau5872 (2019) Et team af forskere med Robotic Systems Lab i Schweiz og Intelligent Systems Lab i Tyskland og USA har fundet en måde at anve
Brug af en maskinlæringsteknik til at gøre en hundelignende robot mere adræt og hurtigereANYmal-robotten. Kredit:Hwangbo et al., Sci. Robot. 4, eaau5872 (2019) Et team af forskere med Robotic Systems Lab i Schweiz og Intelligent Systems Lab i Tyskland og USA har fundet en måde at anve -
 Nissan-Renault på jævnere vej, men fartbump væver:analytikereDet nye hold i Renaults førersæde står over for nogle politisk følsomme beslutninger, med virksomheden forankret i den franske psyke Renaults udnævnelse af en ny lederduo til at erstatte den tilba
Nissan-Renault på jævnere vej, men fartbump væver:analytikereDet nye hold i Renaults førersæde står over for nogle politisk følsomme beslutninger, med virksomheden forankret i den franske psyke Renaults udnævnelse af en ny lederduo til at erstatte den tilba -
 Kortformede streamingplatform Quibi går live, mens forbrugerne trækker sig tilbageQuibi -grundlægger Jeffrey Katzenberg har betegnet platformen som en tv -transformation De hurtige bid af video fra opstartet Quibi med dybe lommer kan blive en ny underholdningsform for smartphon
Kortformede streamingplatform Quibi går live, mens forbrugerne trækker sig tilbageQuibi -grundlægger Jeffrey Katzenberg har betegnet platformen som en tv -transformation De hurtige bid af video fra opstartet Quibi med dybe lommer kan blive en ny underholdningsform for smartphon -
 Lektioner at lære, trods en anden rapport om manglende flyvning MH370 og stadig ingen forklaringMH370 sikkerhedsundersøgelsesrapporter fra transportministeriets hovedkvarter i Putrajaya, Malaysia. Kredit:EPA/Fazry Ismail Den seneste rapport om forsvinden af Malaysia Airlines flyvning MH370
Lektioner at lære, trods en anden rapport om manglende flyvning MH370 og stadig ingen forklaringMH370 sikkerhedsundersøgelsesrapporter fra transportministeriets hovedkvarter i Putrajaya, Malaysia. Kredit:EPA/Fazry Ismail Den seneste rapport om forsvinden af Malaysia Airlines flyvning MH370
- NASA udgiver Kepler Survey Catalogue med hundredvis af nye planetkandidater
- Sådan tegner du en Dendrogram
- Salte oceaner kan forudsige regn på land
- Sådan identificeres upolerede agater
- Billede:Nordøsteuropa
- Fjernelse af malkekøer kan reducere essentiel næringsstofforsyning med ringe effekt på drivhusgas…