


Et nyt forklarligt AI-paradigme, der kunne forbedre menneske-robot-samarbejdet

I spejderudforskningsspillet lærer robotten af menneskelig feedback til forslagene for at tilpasse sig menneskelige værdier. Billedkredit:Ms. Zhen Chen@BIGAI.
Kunstig intelligens (AI) metoder er blevet mere og mere avancerede i løbet af de sidste par årtier og har opnået bemærkelsesværdige resultater i mange opgaver i den virkelige verden. Ikke desto mindre deler de fleste eksisterende AI-systemer ikke deres analyser og de trin, der førte til deres forudsigelser, med menneskelige brugere, hvilket kan gøre en pålidelig evaluering af dem ekstremt udfordrende.
En gruppe forskere fra UCLA, UCSD, Peking University og Beijing Institute for General Artificial Intelligence (BIGAI) har for nylig udviklet et nyt AI-system, der kan forklare dets beslutningsprocesser til menneskelige brugere. Dette system, introduceret i et papir offentliggjort i Science Robotics , kunne være et nyt skridt mod skabelsen af mere pålidelig og forståelig AI.
"Faglet med forklarlig AI (XAI) har til formål at opbygge kollaborativ tillid mellem robotter og mennesker, og DARPA XAI-projektet tjente som en stor katalysator for at fremme forskning på dette område," Dr. Luyao Yuan, en af de første forfattere af papiret , fortalte TechXplore. "I begyndelsen af DARPA XAI-projektet fokuserer forskerhold primært på at inspicere modeller for klassificeringsopgaver ved at afsløre beslutningsprocessen for AI-systemer for brugeren; for eksempel kan nogle modeller visualisere bestemte lag af CNN-modeller, der hævder at opnå en bestemt niveau af XAI."
Dr. Yuan og hans kolleger deltog i DARPA XAI-projektet, som specifikt var rettet mod at udvikle nye og lovende XAI-systemer. Mens de deltog i projektet, begyndte de at reflektere over, hvad XAI ville betyde i bredere forstand, især på de effekter, det kunne have på samarbejder mellem mennesker og maskine.
Holdets seneste papir bygger på et af deres tidligere værker, også udgivet i Science Robotics , hvor holdet undersøgte den indvirkning, som forklarlige systemer kunne have på en brugers opfattelser og tillid til AI under menneske-maskine-interaktioner. I deres tidligere undersøgelse implementerede og testede holdet et AI-system fysisk (dvs. i den virkelige verden), mens de i deres nye undersøgelse testede det i simuleringer.
"Vores paradigme står i kontrast til næsten alle dem, der er foreslået af teams i DARPA XAI-programmet, som primært fokuserede på det, vi kalder det passive maskine-aktive brugerparadigme," fortalte professor Yixin Zhu, en af projektets supervisorer, til TechXplore. "I disse paradigmer skal menneskelige brugere aktivt kontrollere og forsøge at finde ud af, hvad maskinen gør (dermed 'aktiv bruger') ved at udnytte nogle modeller, der afslører AI-modellernes potentielle beslutningsproces."
XAI-systemer, der følger, hvad Prof. Zhu refererer til som "passiv maskinaktiv bruger"-paradigme, kræver, at brugere konstant checker ind med AI'en for at forstå processerne bag deres beslutninger. I denne sammenhæng påvirker en brugers forståelse af en AI's processer og tillid til dens forudsigelser ikke AI's fremtidige beslutningsprocesser, hvorfor maskinen omtales som "passiv".
I modsætning hertil følger det nye paradigme introduceret af Dr. Yuan, Prof. Zhu og deres kolleger, hvad teamet refererer til som et aktivt maskinaktivt brugerparadigme. Dette betyder i bund og grund, at deres system aktivt kan lære og tilpasse sin beslutningstagning baseret på den feedback, det modtager fra brugere i farten. Denne evne til kontekstuel tilpasning er karakteristisk for det, der ofte omtales som den tredje/næste bølge af AI.
"For at få AI-systemer til at hjælpe deres brugere, som vi forventer dem, kræver de nuværende systemer, at brugeren koder i ekspertdefinerede mål," sagde Dr. Yuan. "Dette begrænser potentialet for menneske-maskine-teaming, da sådanne mål kan være svære at definere i mange opgaver, hvilket gør AI-systemer utilgængelige for de fleste mennesker. For at løse dette problem gør vores arbejde det muligt for robotter at vurdere brugernes hensigter og værdier under samarbejdet i realtid, hvilket sparer behovet for at kode komplicerede og specifikke mål til robotterne på forhånd, hvilket giver et bedre menneske-maskine teaming-paradigme."
Målet med systemet skabt af Dr. Yuan og hans kolleger er at opnå såkaldt "værditilpasning". Dette betyder i bund og grund, at en menneskelig bruger kan forstå, hvorfor en robot eller maskine handler på en bestemt måde eller kommer til specifikke konklusioner, og maskinen eller robotten kan udlede, hvorfor den menneskelige bruger handler på bestemte måder. Dette kan forbedre kommunikationen mellem menneske og robot markant.
"Denne tovejs karakter og realtidsydelse er de største udfordringer ved problemet og højdepunktet i vores bidrag," sagde prof. Zhu. "Når du sætter ovenstående punkter sammen, tror jeg, du nu vil forstå, hvorfor vores papirs titel er "In situ tovejs menneske-robot værdijustering."
For at træne og teste deres XAI-system designede forskerne et spil kaldet "spejderudforskning", hvor mennesker skal udføre en opgave i teams. Et af de vigtigste aspekter af dette spil er, at mennesker og robotter skal tilpasse deres såkaldte "værdifunktioner".
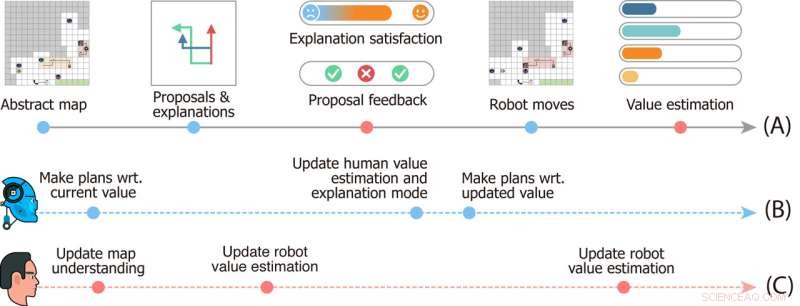
Studiedesign af spejderudforskningsspillet. Tidslinje (A) angiver begivenheder, der sker i en enkelt runde af spillet. Tidslinjer (B) og (C) viser robotternes og brugerens mentale dynamik. Billedkredit:Ms. Zhen Chen@BIGAI.
"I spillet kan en gruppe af robotter opfatte miljøet; dette emulerer applikationer i den virkelige verden, hvor gruppen af robotter formodes at arbejde autonomt for at minimere menneskelige indgreb," sagde prof. Zhu. "Den menneskelige bruger kan dog ikke interagere direkte med miljøet; i stedet fik brugeren en bestemt værdifunktion, repræsenteret ved vigtigheden af nogle få faktorer (f.eks. den samlede tid til at fuldføre tiden og ressourcer indsamlet på farten )."
I spejderudforskningsspillet har holdet af robotter ikke adgang til værdifunktionen givet til menneskelige brugere, og de skal udlede det. Da denne værdi ikke let kan udtrykkes og kommunikeres, skal robotten og det menneskelige team for at fuldføre opgaven udlede den fra hinanden.
"Kommunikationen er tovejs i spillet:På den ene side foreslår robotten flere opgaveplaner til brugeren og forklarer fordele og ulemper for hver enkelt af dem, og på den anden side giver brugeren feedback på forslagene og vurderer hver forklaring, " Dr. Xiaofeng Gao, en af de første forfattere af papiret, fortalte TechXplore. "Disse tovejskommunikation muliggør, hvad der er kendt som værditilpasning."
Grundlæggende skal holdet af robotter for at udføre opgaver i "spejderudforskning" forstå, hvad de menneskelige brugeres værdifunktion simpelthen er baseret på menneskets feedback. I mellemtiden lærer menneskelige brugere robotternes nuværende værdiestimeringer og kan give feedback, der hjælper dem med at forbedre sig og i sidste ende guider dem mod det korrekte svar.
"Vi har også integreret teori om sind i vores beregningsmodel, hvilket gør det muligt for AI-systemet at generere ordentlige forklaringer for at afsløre dets nuværende værdi og estimere brugernes værdi ud fra deres feedback i realtid under interaktionen," sagde Dr. Gao. "Vi gennemførte derefter omfattende brugerundersøgelser for at evaluere vores rammer."
I de indledende evalueringer opnåede systemet skabt af Dr. Yuan, Prof. Zhu, Dr. Gao og deres kollegaer bemærkelsesværdige resultater, hvilket førte til en justering af værdier i spejderudforskningsspillet i farten og på en interaktiv måde. Holdet fandt ud af, at robotten tilpassede sig den menneskelige brugers værdifunktion så tidligt som 25 % inde i spillet, mens brugerne kunne få nøjagtige opfattelser af maskinens værdifunktioner omkring halvvejs inde i spillet.
"Parringen af konvergens (i) fra robotternes værdi til brugerens sande værdier og (ii) fra brugerens estimat af robotternes værdier til robotternes nuværende værdier danner en tovejsværdijustering forankret af brugerens sande værdi," Dr. sagde Yuan. "Vi mener, at vores rammer fremhæver nødvendigheden af at bygge intelligente maskiner, der lærer og forstår vores hensigter og værdier gennem interaktioner, som er afgørende for at undgå mange af de dystopiske science fiction-historier, der er afbildet i romaner og på det store lærred."
Det seneste arbejde fra dette team af forskere er et væsentligt bidrag til forskningsområdet med fokus på udvikling af mere forståelig AI. Det system, de foreslog, kunne tjene som inspiration til skabelsen af andre XAI-systemer, hvor robotter eller smarte assistenter aktivt engagerer sig med mennesker, deler deres processer og forbedrer deres ydeevne baseret på den feedback, de modtager fra brugerne.
"Værditilpasning er vores første skridt mod generisk menneske-robot-samarbejde," forklarede Dr. Yuan. "I dette arbejde sker værditilpasning i sammenhæng med en enkelt opgave. Men i mange tilfælde samarbejder en gruppe agenter om mange opgaver. For eksempel forventer vi, at én husstandsrobot hjælper os med mange daglige gøremål i stedet for at købe mange robotter, hver kun i stand til at udføre én type job."
Indtil videre har forskernes XAI-system opnået meget lovende resultater. I deres næste undersøgelser planlægger Dr. Yuan, Prof. Zhu, Dr. Gao og deres kolleger at udforske tilfælde af menneske-robot værditilpasning, som kan anvendes på tværs af mange forskellige opgaver i den virkelige verden, så menneskelige brugere og AI-agenter kan akkumulere information, som de har tilegnet sig om hinandens processer og evner, når de samarbejder om forskellige opgaver.
"I vores næste undersøgelser søger vi også at anvende vores rammer til flere opgaver og fysiske robotter," sagde Dr. Gao. "Ud over værdier mener vi, at det også ville være en lovende retning at tilpasse andre aspekter af mentale modeller (f.eks. overbevisninger, ønsker, intentioner) mellem mennesker og robotter."
Forskerne håber, at deres nye forklarlige AI-paradigme vil bidrage til at forbedre samarbejdet mellem mennesker og maskiner om adskillige opgaver. Derudover håber de, at deres tilgang vil øge menneskers tillid til AI-baserede systemer, herunder smarte assistenter, robotter, bots og andre virtuelle agenter.
"Du kan for eksempel rette Alexa eller Google Home, når den laver en fejl, men den vil lave den samme fejl, næste gang du bruger den," tilføjede prof. Zhu. "Når din Roomba går et sted hen, du ikke vil have den til at gå og forsøger at bekæmpe den, forstår den det ikke, da den kun følger den foruddefinerede AI-logik. Alle disse forbyder moderne AI at gå ind i vores hjem. Som den første trin viser vores arbejde potentialet i at løse disse problemer, et skridt tættere på at opnå, hvad DARPA kaldte 'kontekstuel tilpasning' i den tredje bølge af AI." + Udforsk yderligere
Giver sociale robotter mulighed for at lære relationer mellem brugernes rutiner og deres humør
© 2022 Science X Network
 Varme artikler
Varme artikler
-
 Big Tech -tilbageslag går i gang med antitrustbevægelserDistrict of Columbia Attorney General Karl Racine (L) og Texas Attorney General Ken Paxton taler under lanceringen af en kartelundersøgelse af store tech -virksomheder uden for USAs højesteret i Was
Big Tech -tilbageslag går i gang med antitrustbevægelserDistrict of Columbia Attorney General Karl Racine (L) og Texas Attorney General Ken Paxton taler under lanceringen af en kartelundersøgelse af store tech -virksomheder uden for USAs højesteret i Was -
 Et nyt spin på organiske halvledereHåndskitse af en organisk lateral spin pumpeanordning. Kredit:Deepak Venkateshvaran og Nanda Venugopal Forskere har fundet ud af, at visse organiske halvledende materialer kan transportere spin hu
Et nyt spin på organiske halvledereHåndskitse af en organisk lateral spin pumpeanordning. Kredit:Deepak Venkateshvaran og Nanda Venugopal Forskere har fundet ud af, at visse organiske halvledende materialer kan transportere spin hu -
 Japans voksende plutoniumlagre vækker frygtFukushima-katastrofen har trykket efterspørgslen efter brændstof til andre atomkraftværker, men Japans plutoniumlagre bliver ved med at vokse Japan har samlet nok plutonium til at lave 6, 000 atom
Japans voksende plutoniumlagre vækker frygtFukushima-katastrofen har trykket efterspørgslen efter brændstof til andre atomkraftværker, men Japans plutoniumlagre bliver ved med at vokse Japan har samlet nok plutonium til at lave 6, 000 atom -
 Menneskelig hjerne supercomputer med 1 million processorer tændt for første gangKredit:University of Manchester Verdens største neuromorfe supercomputer, der er designet og bygget til at fungere på samme måde, som en menneskelig hjerne gør, er blevet udstyret med sin skelsætt
Menneskelig hjerne supercomputer med 1 million processorer tændt for første gangKredit:University of Manchester Verdens største neuromorfe supercomputer, der er designet og bygget til at fungere på samme måde, som en menneskelig hjerne gør, er blevet udstyret med sin skelsætt
- Fem grunde til Indien, Kina og andre nationer planlægger at rejse til månen
- COVID-19 har ændret, hvordan vi sørger
- Med naturbrand truende, Lake Tahoe forbereder sig på nødsituationer
- Hvorfor nogle mennesker skifter politisk parti:Ny forskning
- Kina øjner lanceringen 20.-25. juli for Mars-rover
- Robottråd er designet til at glide gennem hjernens blodkar