


Forbedrede statistiske metoder til high-throughput omics dataanalyse
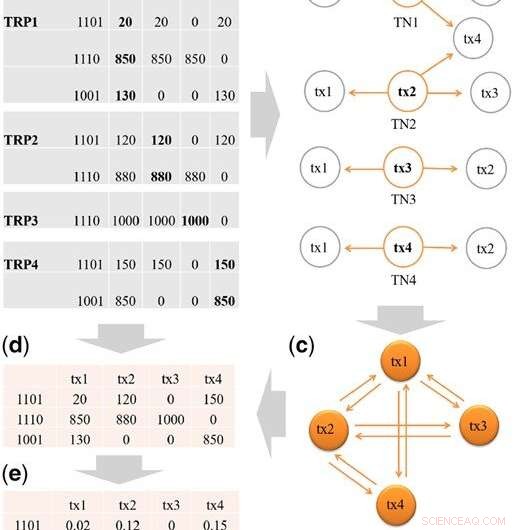
Trin til at konstruere startdesignmatrixen X. (a) TRP'er for tx1, tx2, tx3 og tx4, og oversigten over binære belægningsmønstre fra TRP'erne. Transcript tx5 passerer ikke filtreringen (H = 2,5%) og filtreres fra TRP1. I hvert binært mønster, ciffer 1 betyder, at der er læsninger, der stammer fra en eqclass, og 0 ellers. For eksempel, der er tre eqclasses i TRP1:eqclass1, eqclass2 og eqclass3. For eq1 er det binære mønster 1101, hvilket betyder tre afskrifter, dvs. tx1, tx2 og tx4 har læsninger fra eq1. (b) Transskriptionsnaboer (TN'er) for tx1 til tx4. (c) Illustration af konstruktion af transkriptionsklynge (TC) fra TN'erne. Vi indsamler først TN'erne for tx1, tx2, tx3 og tx4, og tilføj derefter forbindelserne mellem transskriptioner til TC. For eksempel, fra TN1, vi tilføjer forbindelsen af tx1-tx2, tx1-tx3 og tx1-tx4. Til sidst, en TC ville indeholde alle forbindelser mellem transkripter, der deler exoner. (d) Det unikke sæt af binære mønstre bevares, så tre unikke mønstre forbliver:1101, 1001, 1110. Vi udfylder herefter læsetællingerne fra hver kilde TRP. For eksempel, til mønster 1101, i TRP1 er læseantallet 20 for tx1, i TRP2 er læsetællingen 120 for tx2 og i TRP4 er læsetællingen 150 for tx4. (e) Det samlede antal læsninger af hver transkription i (d) er standardiseret til at summere til 1 for at skabe startdesignmatrixen X. Kredit:DOI:10.1093/bioinformatics/btz640
High-throughput omics-teknologi har revolutioneret biologisk og biomedicinsk forskning, og store mængder omics-data er blevet produceret. For det, Der er udviklet beregningsværktøjer til at styre og analysere omics-dataene, og der er store udfordringer i, hvordan man behandler og fortolker omics-dataene på den bedste måde. Wenjiang Deng har arbejdet på at udvikle nye statistiske metoder og algoritmer til omics dataanalyse, ved at bruge både simulerede og reelle kræftdata til at teste metoderne.
Kan du beskrive nogle af resultaterne i dit speciale?
Ja, i mit første studie, vi identificerer flere gener forbundet med overlevelsen af højrisiko neuroblastompatienter, siger Wenjiang Deng, Ph.D. studerende ved Institut for medicinsk epidemiologi og biostatistik, MEB. Neuroblastom er den mest almindelige og dødelige kræftsygdom hos små børn under fem år. Vi mener, at vores resultater vil give væsentlig evidens for behandling og behandling af patienter. Vores resultater kan også være meningsfulde for at forstå sygdommens fysiologiske mekanismer.
Hvorfor valgte du at studere netop dette område?
Vi lever i en æra med "big data, " og high-throughput sekventeringsdata er de fremherskende "big data" inden for life science. Da jeg første gang hørte begrebet omics-data, Jeg var overrasket over dets enorme volumen og det store potentiale i medicinsk forskning. I dag er det ret nemt at producere sekventeringsdata, men vi har stadig brug for effektive og præcise værktøjer til at analysere dem, så jeg besluttede at studere udviklingen af algoritmer i min tid som ph.d. studerende.
Hvad vil du gøre nu?
Efter mit forsvar, Jeg bliver i MEB et stykke tid for at pakke mine manuskripter sammen. Så tager jeg til Shenzhen, Kina, og begynde at arbejde i en bioteknologisk virksomhed, som har til formål at udvikle nye metoder til tidlig diagnosticering af kræftsygdomme. Jeg håber, at vores arbejde der vil bidrage til menneskers generelle sundhed.
 Varme artikler
Varme artikler
-
 Ny kontrakt på $2,5 mia. tildelt til at styre atomvåbenlaboratoriumDette udaterede luftfoto viser Los Alamos National laboratorium i Los Alamos, N.M. Den amerikanske regering har tildelt et hold på to universiteter og et forskningsfirma med kontorer rundt om i verden
Ny kontrakt på $2,5 mia. tildelt til at styre atomvåbenlaboratoriumDette udaterede luftfoto viser Los Alamos National laboratorium i Los Alamos, N.M. Den amerikanske regering har tildelt et hold på to universiteter og et forskningsfirma med kontorer rundt om i verden -
 Sådan drejes et helt nummer til et DecimalHele tal er de tal, du lærte at regne med, startende med nul og gå op: 0, 1, 2, 3, 4 og så videre. Som navnet antyder er der ikke involveret nogen brøk eller decimaler i hele tal, men du kan muligvis
Sådan drejes et helt nummer til et DecimalHele tal er de tal, du lærte at regne med, startende med nul og gå op: 0, 1, 2, 3, 4 og så videre. Som navnet antyder er der ikke involveret nogen brøk eller decimaler i hele tal, men du kan muligvis -
 29, 000 års aboriginal historieMidden-skal udsat på Pike-klippelinjen ved floden Murray. Kredit:Flinders University Den kendte tidslinje for den aboriginalske besættelse af South Australias Riverland-region er blevet enormt udv
29, 000 års aboriginal historieMidden-skal udsat på Pike-klippelinjen ved floden Murray. Kredit:Flinders University Den kendte tidslinje for den aboriginalske besættelse af South Australias Riverland-region er blevet enormt udv -
 På vej tilbage til kontoret? Ikke alle afbrydelser på arbejdspladsen er dårlige for erhvervslivetKredit:CC0 Public Domain Hvis du er på vej tilbage til kontoret efter at have arbejdet hjemmefra, du kan støde på afbrydelser igen, du ikke har oplevet i 18 måneder:Familiens kæledyr erstattes af
På vej tilbage til kontoret? Ikke alle afbrydelser på arbejdspladsen er dårlige for erhvervslivetKredit:CC0 Public Domain Hvis du er på vej tilbage til kontoret efter at have arbejdet hjemmefra, du kan støde på afbrydelser igen, du ikke har oplevet i 18 måneder:Familiens kæledyr erstattes af