


Ny statistisk metode til evaluering af reproducerbarhed i studier af genomorganisation
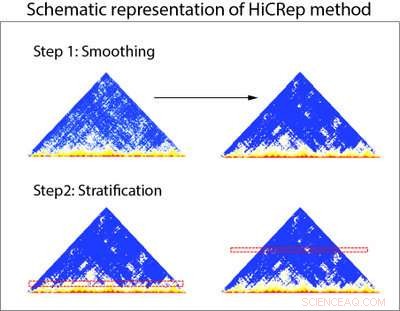
Skematisk fremstilling af HiCRep-metoden. HiCRep bruger to trin til nøjagtigt at vurdere reproducerbarheden af data fra Hi-C eksperimenter. Trin 1:Data fra Hi-C-eksperimenter (repræsenteret i trekantgrafer) udjævnes først for at give forskere mulighed for at se tendenser i dataene mere klart. Trin 2:Dataene er stratificeret baseret på afstand for at tage højde for overfloden af nærliggende interaktioner i Hi-C-data. Kredit:Li Laboratory, Penn State University
En ny statistisk metode til at evaluere reproducerbarheden af data fra Hi-C - et banebrydende værktøj til at studere, hvordan genomet fungerer i tre dimensioner inde i en celle - vil hjælpe med at sikre, at dataene i disse "big data" undersøgelser er pålidelige.
"Hi-C fanger de fysiske interaktioner mellem forskellige regioner af genomet, " sagde Qunhua Li, adjunkt i statistik ved Penn State og hovedforfatter af papiret. "Disse interaktioner spiller en rolle i at bestemme, hvad der gør en muskelcelle til en muskelcelle i stedet for en nerve eller kræftcelle. standardmål til vurdering af datareproducerbarhed kan ofte ikke fortælle, om to prøver kommer fra den samme celletype eller fra fuldstændig urelaterede celletyper. Dette gør det vanskeligt at bedømme, om dataene er reproducerbare. Vi har udviklet en ny metode til nøjagtigt at evaluere reproducerbarheden af Hi-C data, hvilket vil gøre det muligt for forskere at fortolke biologien mere sikkert ud fra dataene."
Den nye metode, kaldet HiCRep, udviklet af et team af forskere ved Penn State og University of Washington, er den første til at redegøre for et unikt træk ved Hi-C-data - interaktioner mellem regioner i genomet, der er tæt på hinanden, er langt mere tilbøjelige til at ske tilfældigt og skaber derfor falske, eller falsk, lighed mellem ikke-relaterede prøver. Et papir, der beskriver den nye metode, vises i journalen Genomforskning .
"Med den enorme mængde data, der bliver produceret i studier af hele genom, det er afgørende at sikre kvaliteten af dataene, " sagde Li. "Med high-throughput teknologier som Hi-C, vi er i stand til at få ny indsigt i, hvordan genomet fungerer inde i en celle, men kun hvis dataene er pålidelige og reproducerbare."
Inde i en cellekerne er der en enorm mængde genetisk materiale i form af kromosomer - ekstremt lange molekyler lavet af DNA og proteiner. kromosomerne, som indeholder gener og de regulatoriske DNA-sekvenser, der styrer hvornår og hvor generne bruges, er organiseret og pakket ind i en struktur kaldet kromatin. Cellens skæbne, om det bliver en muskel- eller nervecelle, for eksempel, afhænger, i hvert fald delvist, på hvilke dele af kromatinstrukturen, der er tilgængelig for gener, der kan udtrykkes, hvilke dele er lukkede, og hvordan disse regioner interagerer. HiC identificerer disse interaktioner ved at låse de interagerende regioner i genomet sammen, isolere dem, og derefter sekvensere dem for at finde ud af, hvor de kom fra i genomet.
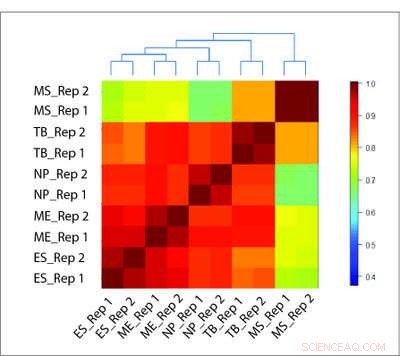
HiCRep-metoden er i stand til nøjagtigt at rekonstruere det biologiske forhold mellem forskellige celletyper, hvor andre metoder fejler. Kredit:Li Laboratory, Penn State University
"Det er lidt ligesom en gigantisk skål spaghetti, hvor hvert sted nudlerne rører ved kan være en biologisk vigtig interaktion, " sagde Li. "Hi-C finder alle disse interaktioner, men langt de fleste af dem forekommer mellem regioner af genomet, der ligger meget tæt på hinanden på kromosomerne og ikke har specifikke biologiske funktioner. En konsekvens af dette er, at styrken af signaler i høj grad afhænger af afstanden mellem interaktionsområderne. Dette gør det ekstremt vanskeligt for almindeligt anvendte reproducerbarhedsmålinger, såsom korrelationskoefficienter, at differentiere Hi-C-data, fordi dette mønster kan ligne meget selv mellem meget forskellige celletyper. Vores nye metode tager højde for denne funktion ved Hi-C og giver os mulighed for pålideligt at skelne forskellige celletyper."
"Dette genlærer os en grundlæggende statistisk lektion, som ofte overses i marken, " sagde Li. "Ganske ofte, korrelation behandles som en proxy for reproducerbarhed i mange videnskabelige discipliner, men de er faktisk ikke det samme. Korrelation handler om, hvor stærkt to objekter er forbundet. To irrelevante objekter kan have høj korrelation ved at være relateret til en fælles faktor. Dette er tilfældet her. Afstand er den skjulte fælles faktor i Hi-C-dataene, der driver korrelationen, gør, at korrelationen ikke afspejler de relevante oplysninger. Ironisk, mens dette fænomen, kendt som forvirrende effekt i statistiske termer, diskuteres i hvert elementært statistikkursus, det er stadig ret slående at se, hvor ofte det bliver overset i praksis, selv blandt veluddannede videnskabsmænd."
Forskerne designet HiCRep til systematisk at redegøre for denne afstandsafhængige egenskab ved Hi-C-data. For at opnå dette, forskerne udglatter først dataene for at give dem mulighed for at se tendenser i dataene mere tydeligt. De udviklede derefter et nyt mål for lighed, der er i stand til lettere at skelne data fra forskellige celletyper ved at stratificere interaktionerne baseret på afstanden mellem de to regioner. "Dette er som at studere effekten af lægemiddelbehandling for en befolkning med meget forskellige aldre. Stratificering efter alder hjælper os med at fokusere på lægemiddeleffekten. For vores tilfælde, stratificering på afstand hjælper os med at fokusere på det sande forhold mellem prøver. "
For at teste deres metode, forskerholdet evaluerede Hi-C-data fra flere forskellige celletyper ved hjælp af HiCRep og to traditionelle metoder. Hvor de traditionelle metoder blev udløst af falske korrelationer baseret på overskuddet af nærliggende interaktioner, HiCRep var i stand til pålideligt at differentiere celletyperne. Derudover HiCRep kunne kvantificere mængden af forskel mellem celletyper og nøjagtigt rekonstruere, hvilke celler der var tættere beslægtet med hinanden.
Sidste artikelAntibiotika-resistente infektioner hos kæledyr
Næste artikelBenchmarking af beregningsmetoder for metagenomer
 Varme artikler
Varme artikler
-
 Hvad ville der ske, hvis en celle ikke havde Golgi-organer?Golgi-kroppen, også kaldet Golgi-apparatet eller Golgi-komplekset, findes i de fleste celler og ligner en stak pandekager. Som distributions- og forsendelsescenter for cellens kemiske produkter ænd
Hvad ville der ske, hvis en celle ikke havde Golgi-organer?Golgi-kroppen, også kaldet Golgi-apparatet eller Golgi-komplekset, findes i de fleste celler og ligner en stak pandekager. Som distributions- og forsendelsescenter for cellens kemiske produkter ænd -
 10 misforståelser om influenzaChefapoteket Ali A. Yasin (til venstre) giver influenzaoplysninger til Juan Castro (højre) efter at have givet ham influenzavaccinen i New York. De ældre er mere sårbare end de unge over for influenza
10 misforståelser om influenzaChefapoteket Ali A. Yasin (til venstre) giver influenzaoplysninger til Juan Castro (højre) efter at have givet ham influenzavaccinen i New York. De ældre er mere sårbare end de unge over for influenza -
 Hvad er arrangement i mikrobiologi?Mikroorganismer er encellede væsener som bakterier, svampe eller skimmel. Disse organismer har en tendens til at formere sig og vokse i grupper, så i stedet for at se på hver enkelt celle alene studer
Hvad er arrangement i mikrobiologi?Mikroorganismer er encellede væsener som bakterier, svampe eller skimmel. Disse organismer har en tendens til at formere sig og vokse i grupper, så i stedet for at se på hver enkelt celle alene studer -
 Mange forhandlere i Midtvesten sælger forkert mærkede invasive vinstokkeI modsætning til indfødt bittersød, orientalsk bittersød kan binde unge træer, efterlader en permanent spiralformet rille i barken og dræber et træ, før det modnes. Kredit:David Zaya Gartnere, der
Mange forhandlere i Midtvesten sælger forkert mærkede invasive vinstokkeI modsætning til indfødt bittersød, orientalsk bittersød kan binde unge træer, efterlader en permanent spiralformet rille i barken og dræber et træ, før det modnes. Kredit:David Zaya Gartnere, der
- Indiske astronomer opdager over 200 variable stjerner
- Californien:Næppe sne, men ikke i tørke igen, endnu
- Typer af kobber
- Edtech-boom forvandler, hvordan indiske børn lærer
- Kunne egernhandel have bidraget til Englands middelalderlige spedalskhedsudbrud?
- At snyde den nye coronavirus med et falsk håndtryk