


Lær AI at lære af ikke-eksperter
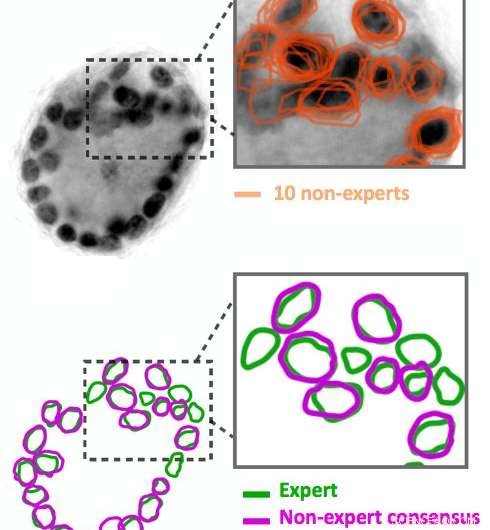
Ikke-ekspert billedanmærkninger er støjende. Ti ikke-eksperter skitserede de mørke sorte cirkler i billedet, som er cellekerner. Deres resultater (vist med orange) stemmer ikke nøjagtigt overens. Vores algoritmer er i stand til at udlede en konsensus-kontur (vist i lilla) fra de støjende data. Sammenlign denne konsensus med ekspertkommentarer af det samme billede (vist med grønt). Kredit:IBM
I dag rapporterede mit IBM-team og mine kolleger på UCSF Gartner-laboratoriet ind Naturens metoder en innovativ tilgang til at generere datasæt fra ikke-eksperter og bruge dem til træning i maskinlæring. Vores tilgang er designet til at gøre det muligt for AI-systemer at lære lige så godt fra ikke-eksperter, som de gør fra ekspertgenererede træningsdata. Vi udviklede en platform, kaldet Quanti.us, der giver ikke-eksperter mulighed for at analysere billeder (en almindelig opgave i biomedicinsk forskning) og oprette et kommenteret datasæt. Platformen er suppleret med et sæt algoritmer, der er specielt designet til at fortolke denne form for "støjende" og ufuldstændige data korrekt. Brugt sammen, disse teknologier kan udvide anvendelserne af maskinlæring i biomedicinsk forskning.
Ikke-eksperter og støjende data
Den begrænsede tilgængelighed af højkvalitets annoterede datasæt er en flaskehals i at fremme maskinlæring. Ved at skabe algoritmer, der kan levere nøjagtige resultater fra annoteringer af lavere kvalitet – og et system til hurtig indsamling af sådanne data – kan vi hjælpe med at afhjælpe flaskehalsen. At analysere billeder for funktioner af interesse er et godt eksempel. Ekspertbilledannotering er nøjagtig, men tidskrævende, og automatiserede analyseteknikker såsom kontrastbaseret segmentering og kantdetektion fungerer godt under definerede forhold, men er følsomme over for ændringer i eksperimentel opsætning og kan producere upålidelige resultater.
Gå ind i crowd-sourcing. Ved at bruge Quanti.us, vi opnåede crowdsourcede billedannoteringer 10-50 gange hurtigere, end det ville have krævet en enkelt ekspert at analysere de samme billeder. Men, som man kunne forvente, annoteringer fra ikke-eksperter var støjende:nogle identificerede korrekt en funktion, og andre var uden for målet. Vi udviklede algoritmer til at behandle de støjende data, at udlede den korrekte placering af en funktion ud fra sammenlægningen af både on- og off-target hits. Da vi trænede et dybt konvolutionsregressionsnetværk ved hjælp af crowd-sourced datasæt, det fungerede næsten lige så godt som et netværk trænet i ekspertkommentarer, med hensyn til præcision og genkaldelse. Sammen med papiret, der beskriver vores tilgang og strategi, vi udgav kildekoden til vores algoritme.
Anvendelser inden for cellulær teknik
Billedanalyse er central for mange områder inden for kvantitativ biologi og medicin. For et par år siden annoncerede vi og vores samarbejdspartnere det NSF-finansierede Center for Cellular Construction (CCC), et videnskabs- og teknologicenter, der er banebrydende for den nye videnskabelige disciplin cellulær teknik. CCC faciliterer tæt samarbejde mellem eksperter fra forskellige discipliner, som maskinlæring, fysik, computer videnskab, celle- og molekylærbiologi, og genomik, at drive fremskridt inden for cellulær teknik. Vi sigter mod at studere og skabe celler, der kan bruges som automatiserede maskiner, eller ad hoc sensorer, at lære ny og vital information om en række biologiske entiteter og deres forhold til det miljø, de lever i. Vi bruger billedanalyse til at lokalisere placeringen og størrelsen af interne cellekomponenter. Men selv med avancerede billedbehandlingsteknikker, den nøjagtige slutning af cellulære understrukturer kan være utroligt støjende, gør det vanskeligt at operere på cellens komponenter. Vores teknik kan bruge disse støjende data til korrekt at forudsige, hvor de relevante cellulære strukturer kan være, muliggør bedre identifikation af organeller involveret i produktionen af vigtige kemikalier eller potentielle lægemiddelmål i en sygdom.
Vi mener, at vores algoritmer er et vigtigt første skridt mod mere komplekse AI-platforme. Sådanne systemer kan bruge yderligere "menneske i løkken"-paradigmer, ved at inddrage en biolog til at rette fejl i træningsfasen, for eksempel, at forbedre ydeevnen yderligere. Vi ser også en mulighed for at anvende vores metode ud over biologi på andre områder, hvor højkvalitets annoterede datasæt kan være knappe.
Denne historie er genudgivet med tilladelse fra IBM Research. Læs den originale historie her.
 Varme artikler
Varme artikler
-
 Multi-joint, personlig blød eksosuit baner nye vejeMulti-joint blød exosuit består af tekstilbeklædningskomponenter, der bæres i taljen, lår og kalve, der styrer mekaniske kræfter fra et optimeret mobilaktiveringssystem, der er fastgjort til en rygsæk
Multi-joint, personlig blød eksosuit baner nye vejeMulti-joint blød exosuit består af tekstilbeklædningskomponenter, der bæres i taljen, lår og kalve, der styrer mekaniske kræfter fra et optimeret mobilaktiveringssystem, der er fastgjort til en rygsæk -
 Fortnites flytter til bots:Hvordan vil det påvirke menneskelige spillere?Dette er cover art til Fortnite:Red verden . Ophavsretten til coverbilledet menes at tilhøre Epic Games. SourceMobyGames I et nyligt træk, Fortnite-producenter annoncerede, at de tilføjer comput
Fortnites flytter til bots:Hvordan vil det påvirke menneskelige spillere?Dette er cover art til Fortnite:Red verden . Ophavsretten til coverbilledet menes at tilhøre Epic Games. SourceMobyGames I et nyligt træk, Fortnite-producenter annoncerede, at de tilføjer comput -
 Tekstbeskeder til Whatsapp – tidlige brugere og inertiKredit:CC0 Public Domain Tekstbeskeder er fortsat et vigtigt middel til elektronisk kommunikation for mange mennesker, der kun kræver den enkleste forbindelse til mobiltelefonnetværket. Alligevel,
Tekstbeskeder til Whatsapp – tidlige brugere og inertiKredit:CC0 Public Domain Tekstbeskeder er fortsat et vigtigt middel til elektronisk kommunikation for mange mennesker, der kun kræver den enkleste forbindelse til mobiltelefonnetværket. Alligevel, -
 7 brugte bilteknologiske funktioner, der kan overraske digDette udaterede billede leveret af Ford viser 2016 Ford Escape, en lille crossover SUV. På de øverste trimniveauer, den leveres med automatisk nedblændede spejle, blindvinkelovervågning og automatiser
7 brugte bilteknologiske funktioner, der kan overraske digDette udaterede billede leveret af Ford viser 2016 Ford Escape, en lille crossover SUV. På de øverste trimniveauer, den leveres med automatisk nedblændede spejle, blindvinkelovervågning og automatiser
- Nyt bevis til støtte for Planet Nine -hypotesen
- Hvorfor dyr vin ser ud til at smage bedre
- Midt i COVID, computing Society udgiver rapport om bedste praksis for virtuelle konferencer
- Sådan beregner du BMI ved hjælp af pounds & Inches
- Cypern, Egypten underskriver aftale om middelhavsgasrørledning
- 6,8-skallet rasler det nordøstlige Japan, ingen tsunamirisiko